
In the parent blog post, we talked about data terms: “Structured, Unstructured, Semi-structured, Sequences, Time-series, Panel, Image, Text, Audio, Discreet, Categorical, Numerical, Nominal, Ordinal, Continuous and Interval”; let’s peel this onion.
Some comments that I hear from engineers/architects:
“My Data is structured. So, it’s computable.” – Not true. Structure does not mean that Data is computable. In general, computable applies to functions, and when used in the context of data, it means quantifiable (measurable). Structured data may contain non-quantifiable data types like text strings.
“All my Data is stored in a database. It’s structured data because I can run SQL queries on this data” – Not always true. Databases can store BLOB-type columns containing structured, semi-structured, and unstructured data that SQL cannot always query.
“Data lakes store unstructured data, and this data is transformed into structured data in data warehouses” – Not Really. Data lakes can contain structured data. Data pipelines extract, transform, and load data into data warehouses. The data warehouse is optimized for multi-dimensional data queries and analysis. Inability to execute queries in data lakes does not imply that Data in the lake does not have structure.
Ok, it’s not as simple as it appears on the surface. Before we define the terms, let’s look at some examples.
Example A: The data below can be classified as structured because it has a schema. The weight sub-structure is quantifiable. “Weight-value” is numeric and continuous type data type, and “weight-units” is categorical and nominal data type.
| name | weight-value | weight-units |
| Nitin | 79.85 | KG |
| Field | Mandatory | Data Type | Constraints |
| name | Yes | String | Not Null Length < 100chars |
| weight-value | Yes | Float | > 0 |
| weight-units | Yes | Enum | {KG, LBS} |
Example B: The data below can be classified as semi-structured because it has a structure but no schema or constraints. Some schema elements can be derived, but the consumer is at the mercy of the producer. The value of weight can be found in “weight-value”, “weight”, or “weight-val” fields. Given the sample, the consumer can infer that the value is always numerical and continuous data type (i.e., float). The vendor of the weighing machine may decide to have their name captured optionally. The consumer will also have to transform “Kgs,” “KG,” and “Kilograms” into a common value before analyzing the data.
| Data Instance A | Data Instance B | Data Instance C |
| { “name”: “Nitin”, “weight-units”: “Kgs”, “weight-value”: 79.85, “vendor”: “Apollo” } | { “name”: “Nitin”, “weight-units”: “KG”, “weight”: 79.85, “vendor-name”: “Fitbit” } | { “name”: “Nitin”, “weight-units”: “Kilograms”, “weight-val”: 79.85, “measured-at”: “14/08/2021” } |
Example C: A JPEG file stored on a disk can be classified as structured data. Though the file is stored as binary, there is a well-defined structure (see table below). This Data is “structured,” but the image data (SOS-EOI) is not “quantifiable” and loosely termed as “unstructured.” With the advance of AI/ML, several quantifiable features can be extracted from image data, further pushing this popular unstructured data into the semi-structured data space.
| JFIF file structure | ||
|---|---|---|
| Segment | Code | Description |
| SOI | FF D8 | Start of Image |
| JFIF-APP0 | FF E0 s1 s2 4A 46 49 46 00 ... | see below |
| JFXX-APP0 | FF E0 s1 s2 4A 46 58 58 00 ... | optional, |
| … additional marker segments | ||
| SOS | FF DA | Start of Scan |
| compressed image data | ||
| EOI | FF D9 | End of Image |
Example D: The Text below can be classified as “Unstructured Sequence” data. The English language does define a schema (constraint grammar); however, quantifying this type of data for computing is not easy. Machine learning models can extract quantifiable features from text data. In modern SQL, machine learning is integrated into queries to extract information from “unstructured” data.
“I must not fear. Fear is the mind-killer. Fear is the little death that brings total obliteration. I will face my fear. I will permit it to pass over me and through me. And when it has gone past, I will turn the inner eye to see its path. Where the fear has gone, there will be nothing. Only I will remain.“
So, the lines are not straight 🙂 Given this dilemma, let’s further define these terms, with more examples:
Quantifiable Data is measurable Data. Computing is easy on measurable data. There are two different types of measurable data – Numerical and Categorical. Numerical Data types are quantitative, and categorical Data types are qualitative.
Numerical data types could be either discreet or continuous. “People-count” cannot be 35.3, so this Data type is discreet. “Weight-value” is always approximated to 79.85 (instead of 79.85125431333211), and hence this Data type is continuous.
Categorical data type could be either ordinal or nominal. In “Star-rating,” a value of 4 is higher than 3. Hence, the “star rating” data is ordinal as there is an established order in ratings. The quantitative difference between ratings is not necessarily equal. There is no order in “cat,” “dog,” and “fish”; hence, “Home Animals” is nominal data type.
| Parent Category | Child Category | Example |
| Numerical | Discreet | { “people-count”: 35 } |
| Numerical | Continuous | { “weight-value”: 79.85 } |
| Categorical | Ordinal | 5 STAR RATING = {1,2,3,4,5} {“star-rating”: “3”} |
| Categorical | Nominal | Home Animals = {“cat”, “dog”, “fish”} {“animal-type”: “cat”} |
Non-Quantifiable Data is Data where the measurable features are implicit. The Data is rich in features, but the features need to be extracted for analysis. AI is changing the game of feature extraction and pattern-recognition for such data. The three well-known examples in this category are Images, Text, and Audio. The latter two (Text and audio) are domains of natural language processing (NLP), while Images are the domain of computer vision (CV).
Quantifiable and Non-Quantifiable data can be composed together into structures. The composition may be given a name. Example: A “person” is a composite data type of quantifiable (i.e., weight) and non-quantifiable (i.e., name) data types.
When data is composed with a schema, it is loosely called “structured” data. Any composition without a schema is loosely called “semi-structured” data.
Structured or Semi-structured data with non-quantifiable fields is called unstructured data. In this spirit, example C is unstructured. Also, the quote about data lakes storing “unstructured” Data is true. The data might have a structure with schema but cannot be queried in place without loading into a data cube in the warehouse. The lines blur when modern lake-houses that query data in-place at scale.
Data can also be composed together into “Collection” data types. Sets, Maps, Lists, and Arrays are examples of some collections. “Collections” with item order and homogeneity are called sequences. Movies and Text are sequences (arrays of images and words). In most cases, all data generated in a sequence is usually from the same source.
Sequences ordered by time are called time-series sequences, or just time-series for short. Sensor data that is generated periodically with a timestamp is an example of time-series data. Time-series data have properties like trend and seasonality that we will explore in a separate blog post. A camera (sensor) generates a time-series image data feed with a timestamp on every image. This feed is a time-series sequence.
Some visuals will help to clarify this further:

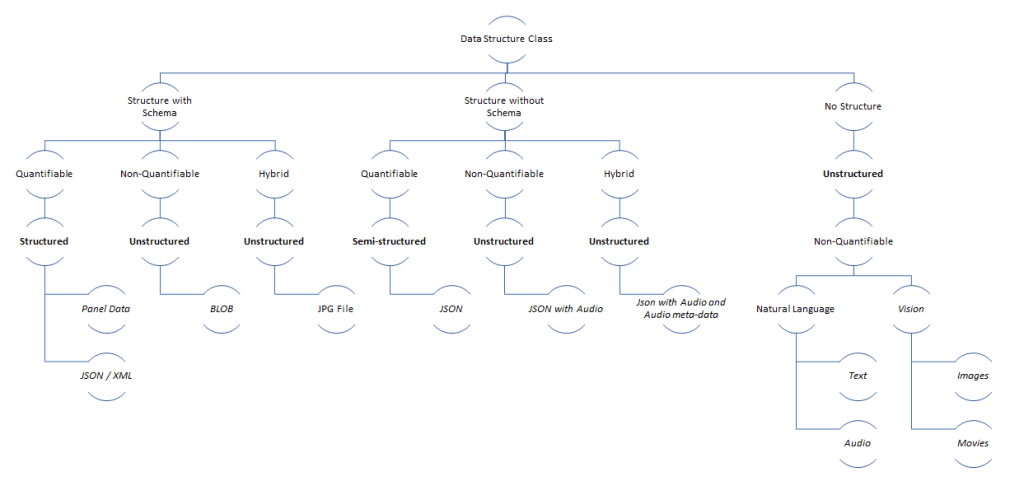
JSON and XML are data representations that come with or without schema. It’s incorrect to call all JSON documents semi-structured, as they might originate from a producer that uses well-defined schema and data typing rules.
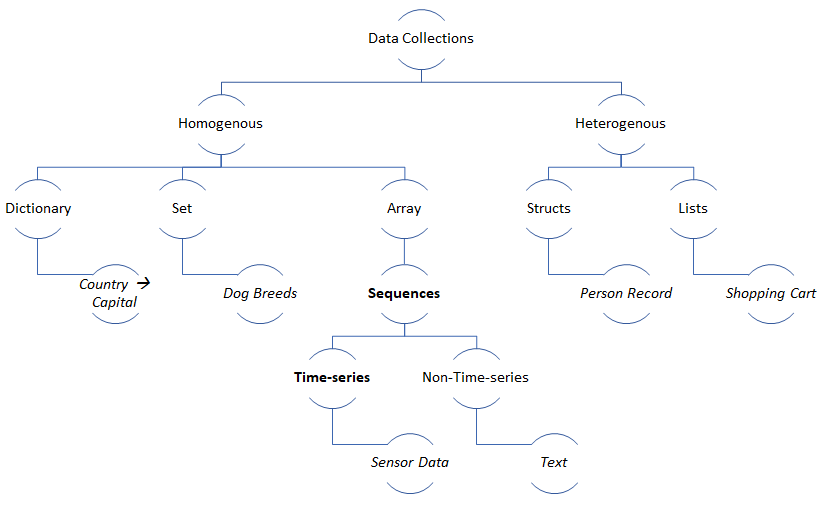
Hope this post helps to understand the “data measurement and composition vocabulary“. You can be strict or loose about classifying data by structure based on context—however, it’s critical to understand the measurement class.
Only measurable data generates insights.
After all that rant, let’s try to decipher “logs” data-type.
- “Performance Event Logs” generated by an application with fixed fields like {id: number, generated-by: application-name, method: method-name, time: time-since-epoch} is composed of quantifiable fields and constrained schema. So, it belongs to the “Structured Data” class.
- “Troubleshooting Logs” generated by an application with fields like {id: number, generated-by: application-name, timestamp: Date-time, log-type: <warn, info, error, debug>, text: BLOB, +application-specific-fields} is composed of quantifiable and non-quantifiable fields, without a constraining schema. Some applications may add additional fields like – API name, session-id, and user-id. Strictly, this is “unstructured” data due to the BLOB but loosely called “semi-structured” data.
Measurement-based data type classification and composition of types into structures do not convey semantics. We will cover semantics in our next blog!
