Every strategy deck has the same picture: tool, automation, workflow, agent, agentic process — an arrow climbing to the right. The message is that you climb it; that running agents make you more advanced than running rules. This confuses cost with progress. Autonomy is not a higher floor. It is an expensive cell to grow, and most teams are growing it where bone would have done.
The deck is wrong because the arrow is wrong. Software is not a building you climb. It is a body you compose. Bodies are not built from one tissue arranged in order of sophistication — they are built from different cells, each shaped for a different job, joined into tissues and organs that handle specific loads. There is no “advanced cell,” only the right cell for the work. A neuron is not nobler than a red blood cell. It is more expensive to run, and you do not want one carrying oxygen around your body.
The system is designed for the workload
Every engineer knows this from another life. You don’t run a database on a compute-optimized VM, or a graphics workload on a memory-optimized one. You don’t put a long-running batch job on the same node as a latency-sensitive API. You match the machine to the work — compute-heavy here, I/O-heavy there, GPU there, memory there — and you size each one to what it actually has to do, not to what looks impressive on the architecture diagram.
Biology has been doing this for half a billion years. A cell is a workload-specific machine. Bone cells lay down structure slowly. Skin cells turn over fast because they wear out fast. Red blood cells are stripped down to a single job — they don’t even keep their nucleus, because nothing they do requires one. The body never spent metabolic budget on capabilities it didn’t need at the work site. Doing that would have been a waste — and in evolution, waste loses.
AI has forgotten both lessons. I am not against agents. I build them, and the good ones are worth every rupee. The point is narrower: autonomy is something you pay for, and most teams are spending it on parts of the body that only ever needed bone — because sophistication is flattering, not because the load demanded it.
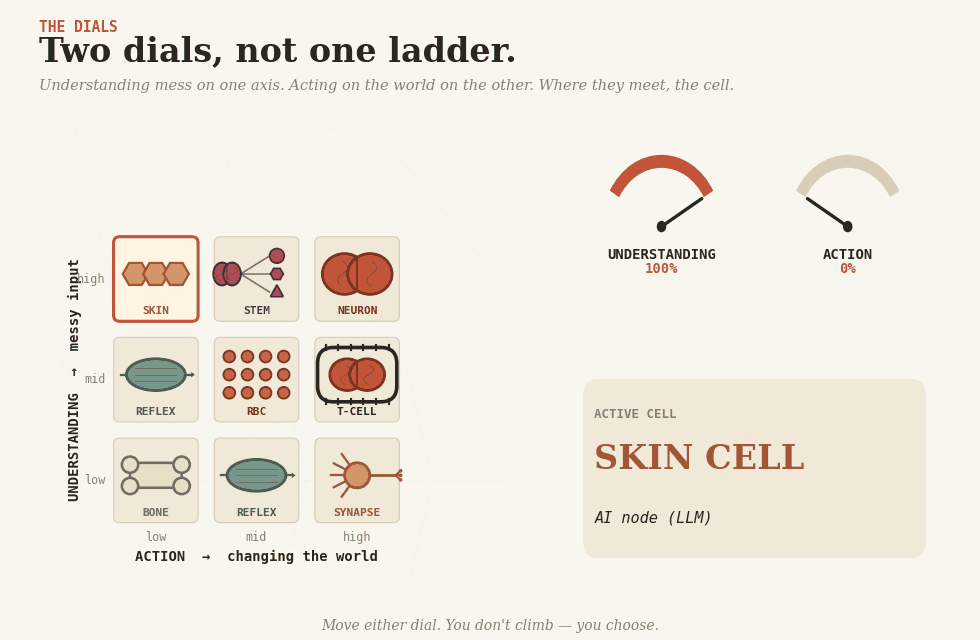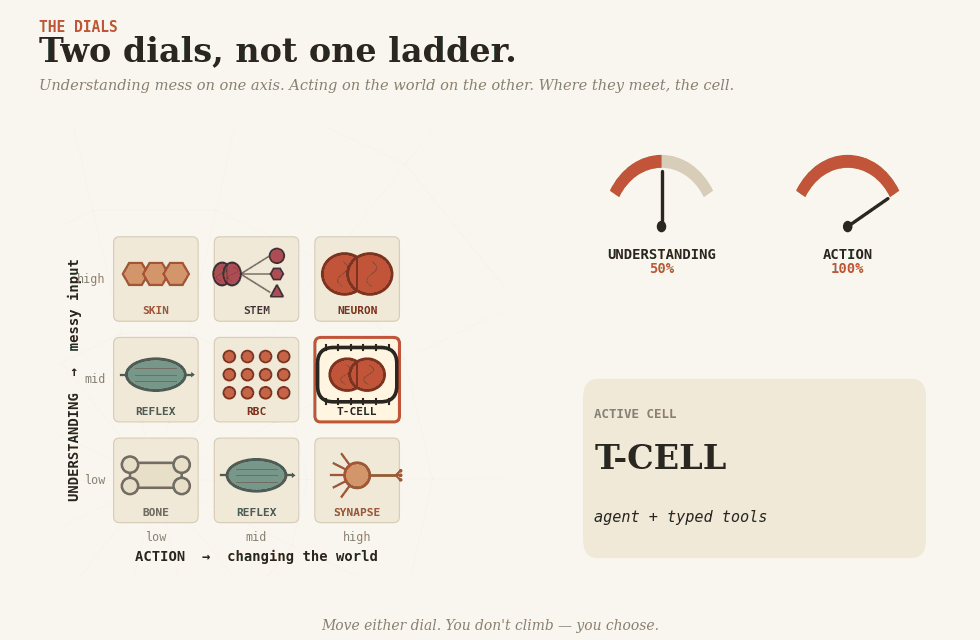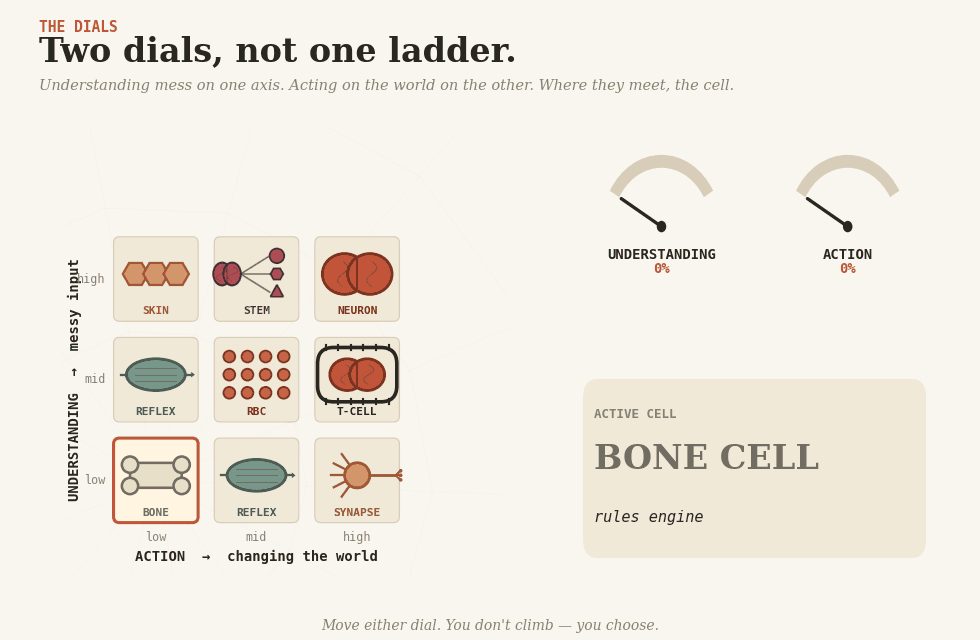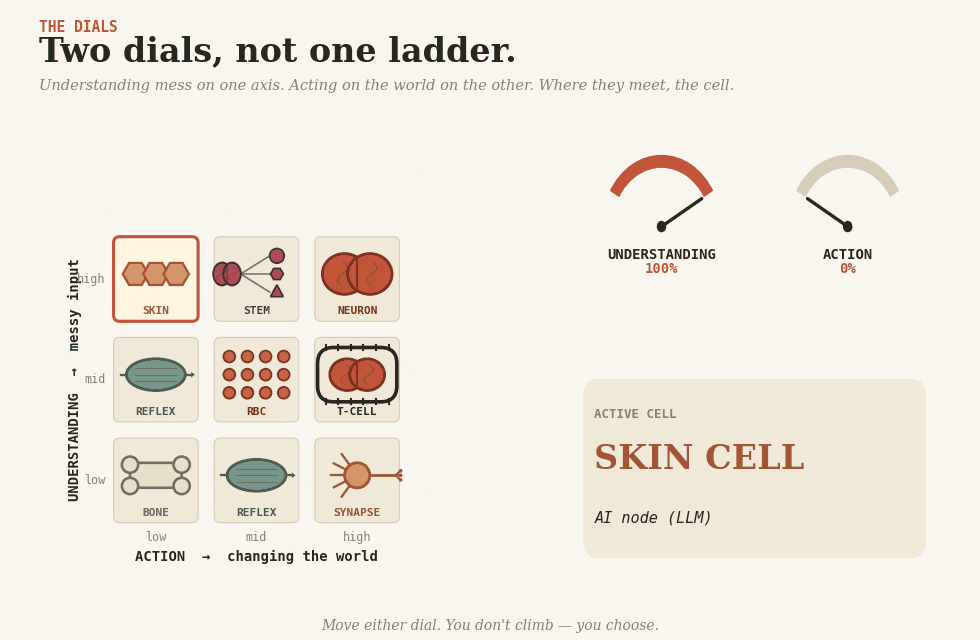
Two dials
There are two dials. One controls understanding — making sense of messy human input. The other controls action — changing something in the world. They are not the same dial, and the whole craft is in keeping them apart.
Let the agent read the messy request; let rules make the clean decision.
Eight cells
Real systems are tissues, made of specialized cells. Here are the eight you have to choose from.
Bone cell (osteocyte) — rules. Hard, structural, deterministic. The skeleton everything else hangs from: eligibility checks, fee tables, routing, validation — anything you can enumerate honestly. Cheap, reproducible, brittle, the day reality moves in a direction it didn’t anticipate.
Skin cell (keratinocyte) — AI inside a fixed workflow. The body’s interface with the messy outside: senses, classifies, extracts. The workflow around it decides what happens next. Most LLM-based production AI is skin. The trap is that a 95%-accurate skin cell, called a million times, produces 50,000 wrong readings, and the surrounding tissue has nothing to catch them.
Reflex cell (trained muscle memory) — a trained model running automatically. A classifier, a fraud-score, a recommendation — fired without reasoning, without an LLM call, often without anyone noticing it’s there. Reflex is most of the AI that a large company actually has. Cheap, fast, and dangerous, the way every reflex is dangerous: it does the same thing every time, including when it shouldn’t. Retrain it when the world drifts, or it will keep flinching at last year’s shadow.
Brain cell (neuron) — unconstrained agent. Reasons end-to-end, decides, acts. Buys coverage of cases you couldn’t write down. Pays in reproducibility, audit, and the same input on two Tuesdays, giving two different answers. Right for prototypes and small blast radii. Wrong in a kneecap.
T-cell (lymphocyte) — an agent with typed tools. T-cells act only through receptors that fit specific shapes; they will not engage anything else. That is exactly the pattern. The agent reasons freely; every action passes through a typed tool with hard constraints. The agent may want to refund 50,000; the refund tool refuses any amount above 500 without a human signature. Typed tools, constrained actions, permissions held outside the model — the kind of pattern MCP can support, if the system around it is designed properly. An impressive agent with no receptors is the easy half of the job.
Nerve cell (at the synapse) — human-in-the-loop. A nerve cell that hands a signal across to a different system — across the gap to a conscious human — and waits. The slowest pattern, often the right one — for expensive, irreversible decisions. The failure mode is rubber-stamping. After approval number five hundred, nobody reads.
Red blood cell (erythrocyte) — homogeneous multi-agent. Many copies of one cell, scaled across a workload — a thousand support tickets, an overnight backlog. The trap is mistaking parallelism for cleverness. Red blood cells spread the autonomy tax across the workload; they do not pay it.
Stem cell — heterogeneous multi-agent. Differentiates into specialists for a task and recombines. A planner dispatches diagnostic, retrieval, and drafting agents; their work composes back. Right where the problem truly decomposes — research, code review, multi-stage analysis. Wrong when it is one agent split into several roles because one wasn’t impressive enough.
Composing the body
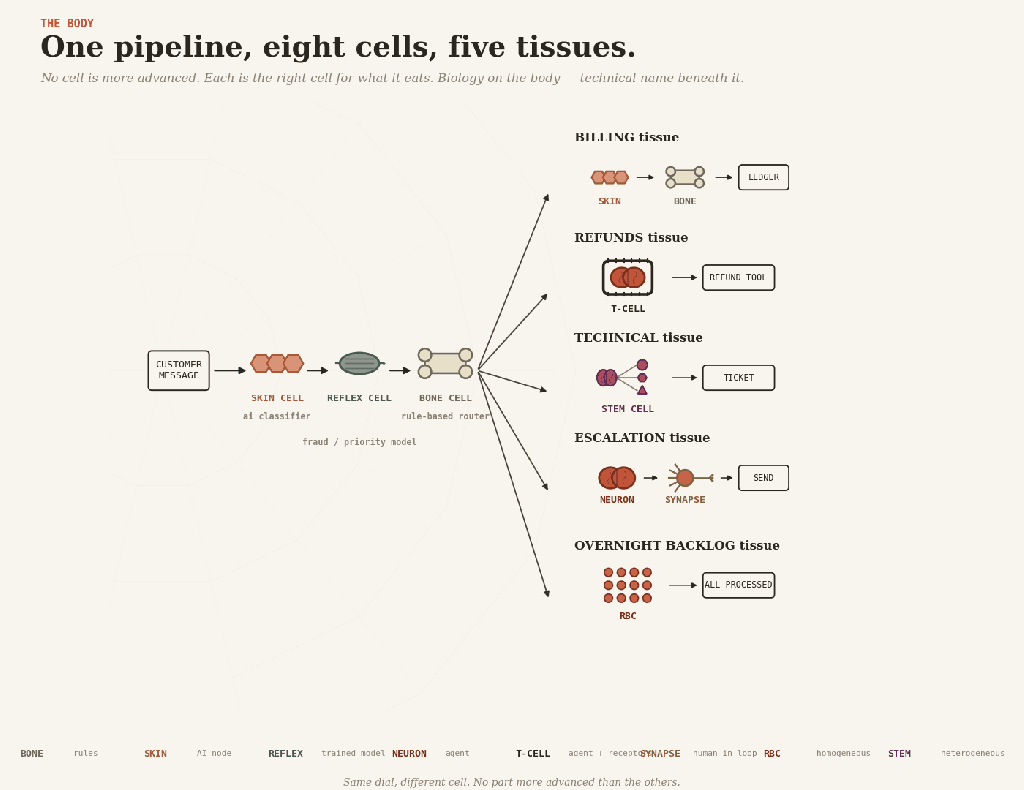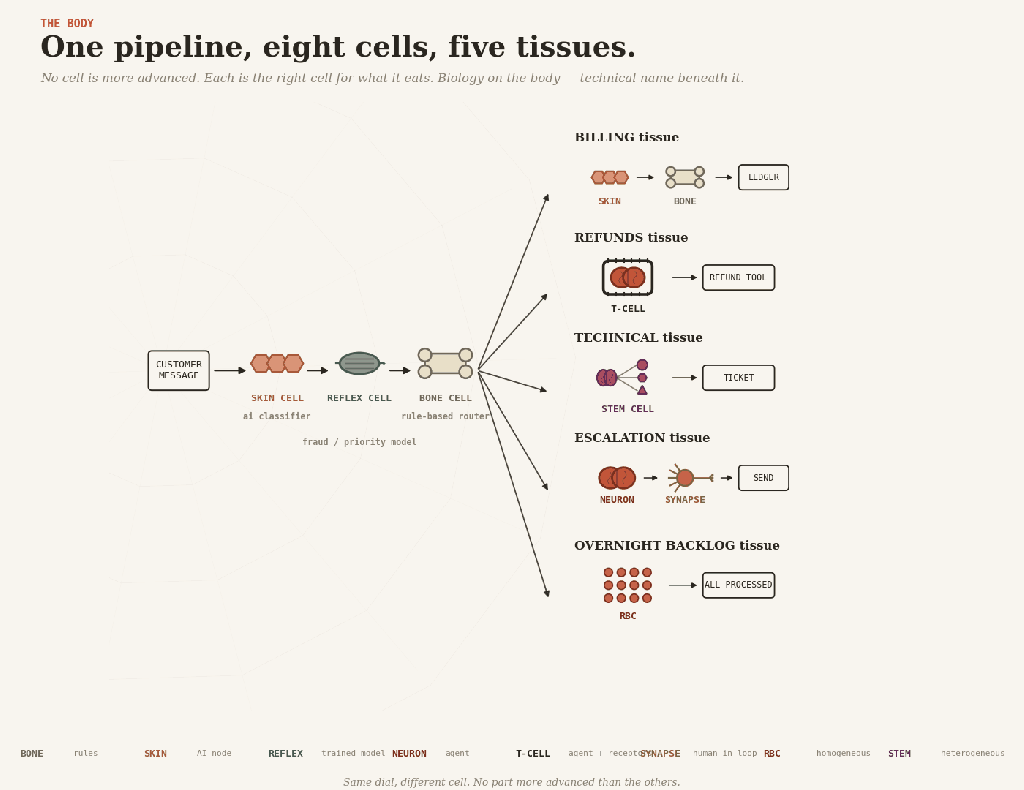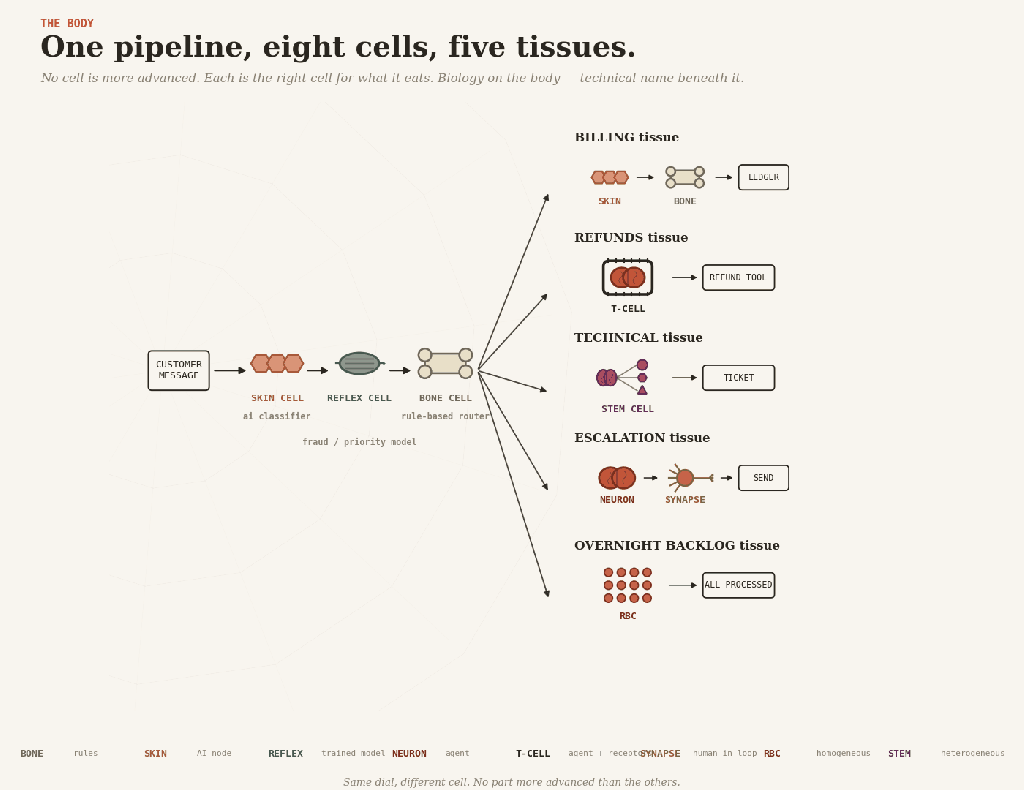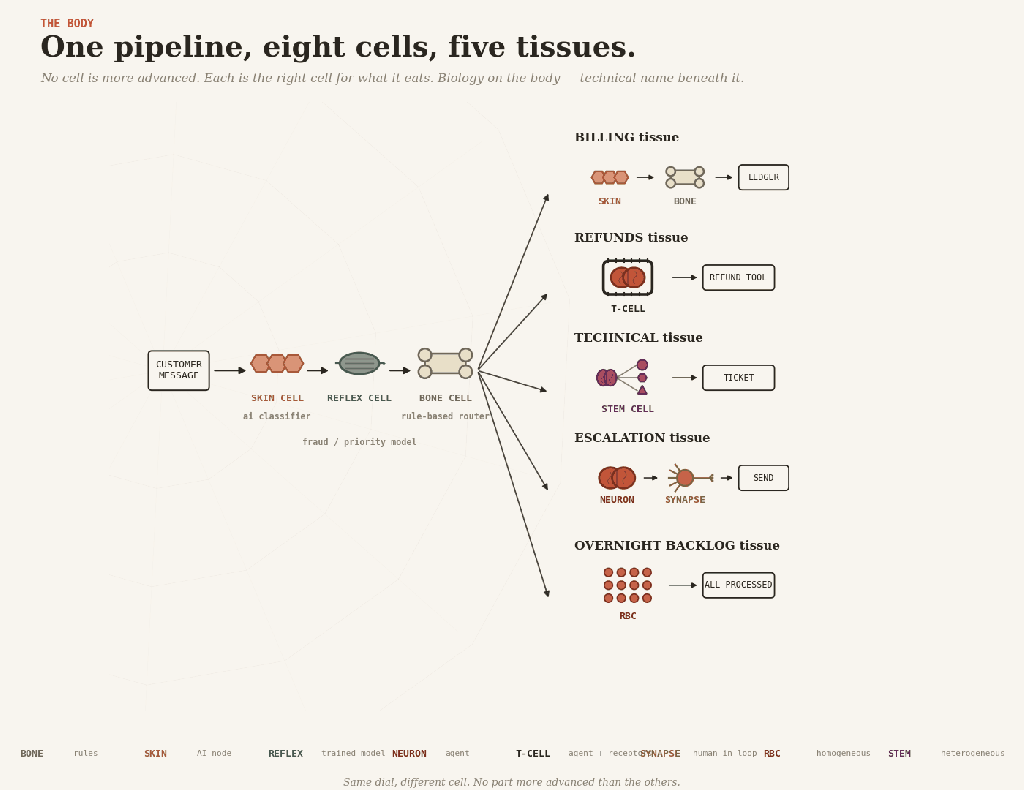
A customer-service pipeline shows the cells at work together.
A message arrives — messy, human, structured by nobody. Skin cells read it, classifying the intent. Quietly, in the background, a reflex scores it for fraud and priority. Bone routes it, sending billing one way, refunds another, technical a third, and escalations a fourth.
Then each branch grows different tissue.
Billing is skin and bone: extract the invoice fields, validate, and post to the ledger. No brain anywhere.
Refunds are T-cell tissue: the agent reasons about the case, but the refund receptor only fits payments below the limit. Anything bigger gets handed up.
Technical is stem-cell tissue: a planner dispatches diagnostic and knowledge-base agents, and their findings compose into a ticket.
Escalation is brain and synapse: the agent drafts a careful reply, a human reads and approves it before it ships.
And overnight, a red blood cell swarm processes the low-priority backlog while everyone sleeps.
One pipeline, eight cells. None is more advanced than the others. Each is the right cell for what it eats.
The cost of using the wrong cell
Take one decision — refund a customer — and watch what happens when you choose wrong.
As bone: refund within 30 days with receipt; unused. Reproducible, instantly explainable, brittle on day thirty-one. The thirty-first-day customer leaves.
As synapse: bone handles the easy 90%, a human handles the awkward 10%. Slower, humane, still explainable, paid for by customers, not driven away by bone’s bluntness.
As an unconstrained brain, it reads the complaint, weighs the loyalty score, and issues the refund. Useful, and expensive in ways most teams don’t price. Reproducibility falls. Why it was refunded is now a paragraph of reconstructed reasoning, not a line of code. Proving it didn’t quietly favor one customer segment is now real work. You bought judgment, and paid for it in four other qualities.
That trade has to be seen. Repeat the same dial-up across forty decisions, and the problem in production isn’t that any one agent is wrong — it’s that you grew judgment where a checklist would have done, and nobody can reproduce what happened on Tuesday.
The objection
Pure-bone systems are brittle precisely because they are complete. The old RPA bots broke the instant a button moved two pixels. Doesn’t that argue for agents everywhere?
No. It argues for honesty about which inputs are actually fixed. Those bots failed because someone called an open problem closed and encoded it in the most rigid form available. Bone where skin was needed. The answer is not to replace all bone with brain. It is to grow the right cell for the load — and never let the convenience of one talk you into misusing the other.
The discipline
The deck’s arrow points the wrong way. The goal was never to climb to “fully agentic.” For every decision in a body of work, the goal is the simplest cell that still carries the load — and the nerve to hold that line against the steady, friendly pressure to add a little more judgment to things that worked fine.
The nerve is the hard part, because the agent is the most flattering shape we have. It looks modern. It signals to the board that we are doing AI, not merely thinking carefully. Reaching for it when the load did not demand it is not a technical mistake. It is a small dishonesty about the shape of the problem — picking impressive material to make it seem like the kind of team that uses it.
Use bone where the answer can be described. Train the reflex where the pattern is stable. Put skin where the world is messy, and the rulebook around it can still decide. Use T-cells where the agent must reason but must not run free. Connect a synapse where being wrong is expensive and final. Spin up red blood cells where the same work repeats at scale. Compose stem cells where the problem genuinely decomposes. Keep a clear record of all of it.
Grow brain everywhere instead, and you have not built something advanced. You have built something heavy, costly, harder to trust, and slightly vain — paying the autonomy tax for work that bone would have carried.