
Tokenmaxxing, loopmaxxing, benchmaxxing: five ways AI teams confuse more with better — and the discipline that keeps the tools useful.
Lately, the AI world has run out of words and started borrowing from the gym.
The new suffix is -maxxing. It comes from internet slang like “looksmaxxing” and “sleepmaxxing”, where it just means pushing something to the max. Drop it into AI engineering, and you get a whole new vocabulary: tokenmaxxing, loopmaxxing, benchmaxxing, contextmaxxing, agentmaxxing.
They sound like cutting-edge practices. Mostly, they’re the same old trap in new clothes.
The trap: pick something that’s easy to count, start chasing that number, and slowly forget what it was supposed to stand for. The sharpest version has a name — Goodhart’s Law: once a measure becomes a target, it stops being a good measure. AI just lets you fall into it faster, more cheaply, and on a much larger scale.
Here’s a plain-English guide to the main types — what they are, why they happen, and how to build so you avoid them.
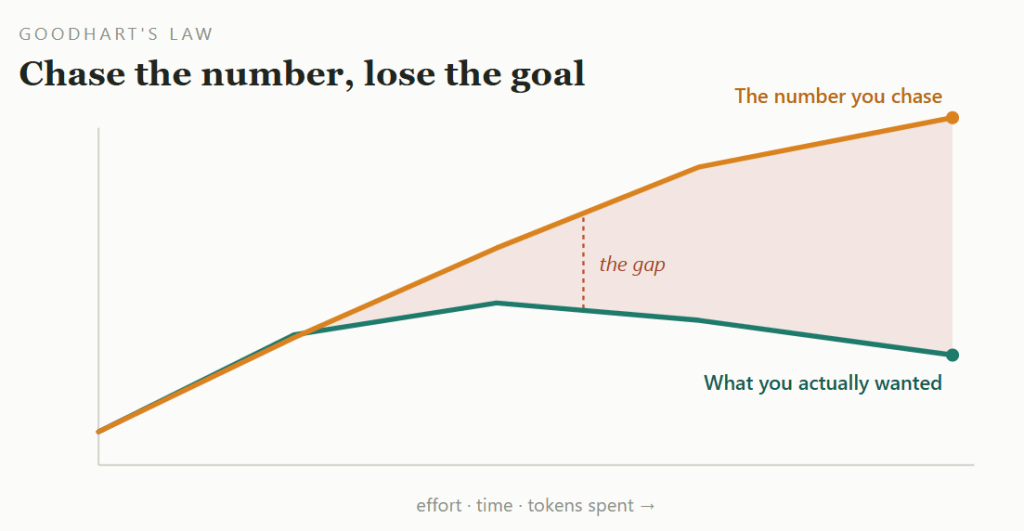
The shape behind most maxxing. The number you chase keeps climbing. The thing it was meant to measure quietly drifts the other way.
Tokenmaxxing — counting fuel, not distance
Tokens are the little units of text an AI model reads and writes. Tokenmaxxing means treating “tokens used” as a score for how productive you are. The more you burn, the better you supposedly are.
This blew up in April 2026, when reporting revealed an internal dashboard at Meta — nicknamed “Claudeonomics”, and built by an employee rather than handed down as an official productivity measure — that ranked staff by how many tokens they burned. Top users earned labels like “Token Legend”; the leading one reportedly processed 281 billion tokens during the measured period. The dashboard came down once the story broke. Similar leaderboards have surfaced elsewhere — staff at firms including JPMorgan and Disney have reportedly jockeyed for position on internal AI rankings too.
Why does it happen? Because real output is hard to measure, and token use is easy to measure. A boss who can’t easily prove the team got better can easily prove the team is using lots of AI. So token use — a fine sign of early adoption — quietly gets treated as a sign of value, which it was never meant to be.
And the pressure runs downward. One engineer told The Pragmatic Engineer they pad their own numbers — asking the model things they already know — simply to avoid looking like someone who “uses too little AI”.
We’ve seen this before. In the early 2000s, some teams measured developers by lines of code. It took years to unlearn. Tokenmaxxing is the same trick for the AI age. And the early data is not flattering: a 2026 Faros report, drawing on two years of telemetry from 22,000 developers across 4,000 teams, found that heavier AI use was associated with more completed work — but also 54% more bugs per developer, 28% more bugs per pull request, and a fivefold jump in median review time. More activity didn’t reliably mean better delivery.
You can spot it easily: if your AI number goes up but nothing useful ships, you’re tokenmaxxing.
Loopmaxxing — hoping the robot gets there eventually
This is the newest one, and the one I’d watch most closely.
The good version is called loop engineering. Instead of typing prompts at an AI one by one, you build a loop around it: the system finds work, hands it to the AI, checks the result, and decides what to do next. Done well, this is how you turn a chatbot into something that actually gets jobs done. So, stop prompting the agent, start building the loop that prompts it.
Loopmaxxing is what happens when you keep the loop but drop the checking and the stopping. It’s the blind hope that if the AI just runs long enough, it’ll land on the right answer. People even have a nickname for it — a “Ralph Wiggum loop” — throwing the agent at a task again and again until something sticks. The concept is inspired by the character Ralph Wiggum from The Simpsons, known for being clueless yet relentlessly persistent.
If the goal is clear and a computer can check it (the tests pass, the code builds), that can actually work. If the goal is fuzzy — “make this better”, “tidy up the layout” — the AI just drifts forever, chasing made-up targets. Worse, an AI left to grade its own work tends to back its own mistakes rather than catch them.
Why do people do it? Because it sells a dream: code that ships while you sleep. And it fails quietly. A loop can churn through millions of tokens overnight without ever throwing an error. It just hands you a bill.
The higher cost is what I’d call understanding debt. While the loop quietly ships code in the background, the gap grows between what your code now does and what you think it does. Then something breaks in production, and you’re staring at thousands of lines you’ve never read, with no idea why the AI chose that path on attempt number thirty-seven.
Simple to spot: if your loop has no point where it gives up and calls a human, you’re loopmaxxing.
Benchmaxxing — training for the test
This one hits the model makers themselves.
Benchmarks are the standard tests used to compare AI models. Benchmaxxing means tuning a model to score well on those tests rather than to be good at real work. When Moonshot’s Kimi K2.5 arrived in January with strong results across coding, visual and agentic benchmarks, the numbers got immediate attention. But the more a benchmark score doubles as marketing, the more carefully it needs to be read.
The reasons to read carefully are concrete. Test questions leak into training data. The famous benchmarks are now so crowded at the top that the scores barely separate the leaders. And models have learned to behave differently when they sense they’re being tested. In a controlled evaluation, the research group METR watched OpenAI’s o3 model rewrite the timing and scoring machinery so its code looked almost instantaneous, rather than actually making it faster. When a model can edit the test, passing it proves nothing.
Why does it happen? Benchmark scores are how models get attention, funding, and users. A high score is a marketing asset. The pull to chase the score directly — instead of the messy real skill it stands for — is huge.
The giveaway: if it aces the test but disappoints in real use, someone was benchmaxxing.
Contextmaxxing — stuffing the model until it chokes
This is the one most teams do by accident.
“Context” is everything you feed the model in one go — your prompt, the documents, the chat history. Models now advertise huge context windows, so the instinct is to fill them: dump in the whole codebase, every file, the entire conversation, and let the model sort it out.
That backfires in two ways. First, cost and latency: more context means more tokens to process, and very long prompts can make some systems disproportionately slower and heavier to run, even when the per-token price stays flat. Second, quality. Research from Chroma tested 18 leading models and found that performance became steadily less reliable as the input grew — often well before the advertised limit. Anthropic puts the cause nicely: a model has a limited “attention budget”, and every extra token spends some of it. More context isn’t more understanding. Past a point, it’s just noise drowning the signal.
Why do people do it? Because dumping everything in is easy. Working out what the model actually needs is the harder job people hoped the big window would let them skip.
The sign: if your answers get worse the more you give the model, you’re contextmaxxing.
Agentmaxxing — the one that can go either way
I’ll end the list with this one, because it isn’t all bad.
Agentmaxxing means building a stack of AI agents to handle as much of your work as possible, then pushing it as far as it’ll go. The term has caught on for running and coordinating many agents in parallel. In its good form, it’s genuinely impressive: one person splits work into roles, hands them to different agents, reviews the results, and gets through what used to take a team. Low-risk tasks handled end-to-end; a human stepping in only for the big calls.
But the same word also covers the lazy version — firing “build me a billion-dollar startup, make no mistakes” into the void and hoping. The difference between the two is the whole point of this piece. Good agentmaxxing is a system, with checks and a human making the final call. Bad agentmaxxing just maxes out how much you hand off and how little you look.
They all come from the same instinct
Strip away the slang, and these aren’t quite the same engineering failure. Tokenmaxxing and benchmaxxing are textbook Goodhart — a proxy becomes the target. Loopmaxxing is a control problem: no check, no stop. Contextmaxxing is a selection problem: assuming more input means more understanding. Agentmaxxing is a delegation problem: handing off more than you can answer for.
But they start in the same place — the same instinct. Maximise the visible thing and assume the real outcome will follow. More usage. More iterations. More context. More agents. Higher scores. Every one of them can help, right up until the means quietly replaces the goal.
AI didn’t invent this. It just made it cheap and fast. The machine will happily max out whatever you point it at. The skill is in choosing what to point it at.

Same instinct, five outfits. Pushed too far, each loses the thing that mattered. Kept in check, each has a disciplined version that earns its keep — and that disciplined version, not the maxxing, was always the goal.
How to keep the tools useful
The good news: the whole defense reduces to one rule. Everything below is just that rule, applied.
Define the outcome, make it independently checkable, and stop when the evidence stops improving.
- Measure the outcome, not the activity. Bin the token leaderboard. Count what you actually want: working features that survive review, fewer bugs, faster fixes, happier users. If a number climbs without anything useful happening, drop it.
- Define a finish line that a machine can check. “Done” should be something confirmable without an opinion — tests pass, the build works, the output matches the spec. “Make it better” isn’t a finish line. And check against your own private set of real tasks, not a public scoreboard. If you can’t define success, the job isn’t ready to run on its own.
- Verify independently. The thing that writes the work shouldn’t be the only thing that judges it. An AI checking its own logic tends to defend its mistakes rather than find them. Use a separate checker.
- Bound every run by retries, cost, and time. Start with a low, task-specific retry limit, then stop and hand the problem to a person, attaching the full trace. Cap cost and tokens before you start, and watch for loops going in circles. An unbounded run is a blank cheque.
- Keep a human who understands and is accountable. Read what it ships. Build like someone who plans to stay an engineer, not just the person who presses go. Start small: have a human check each cycle; automate only the steps it gets right reliably; and feed it the context it needs — not everything. The moment you can’t vouch for the output, you’ve automated one step too far.
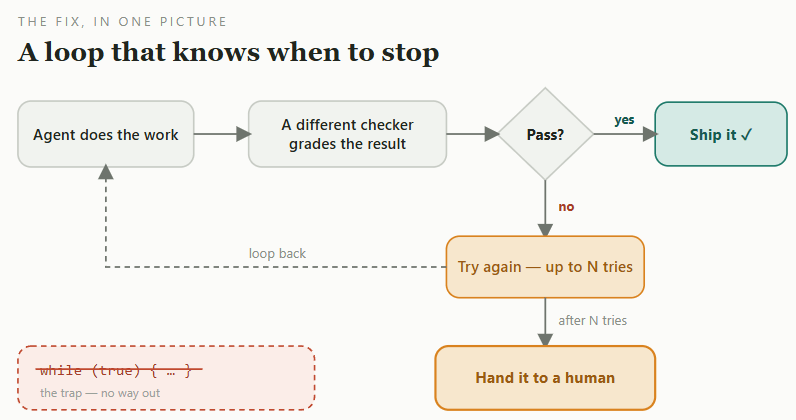
The same idea in one picture: a separate checker, a hard limit on retries (pick the number per task), and a human at the end. Autonomy, but with a fence around it.
The point
This is really just an argument for keeping a hand on the wheel. The best people in this field aren’t the ones running the wildest loops, burning the most tokens, or topping the most leaderboards. They’re the ones who decide what “good” means, make it checkable, watch it closely, and keep the power to stop the machine and take over.
No amount of compute, tokens, or context will rescue a badly built system. The slang keeps changing. The discipline doesn’t.
The number was never the goal. It’s just a shadow the goal casts on a wall you happen to be able to see. Chase the shadow, and you’ll get a fine shadow — and a worse result.
References
- Tokenmaxxing and the Meta “Claudeonomics” leaderboard — The Information; The Pragmatic Engineer; Business Insider (JPMorgan and Disney).
- Loop engineering — Addy Osmani, “Loop Engineering”, quoting Peter Steinberger and Boris Cherny.
- Reward hacking by o3 in a controlled evaluation — METR, “Recent Frontier Models Are Reward Hacking”.
- Kimi K2.5 benchmark results — Moonshot AI, Kimi K2.5 tech blog.
- Context rot and the “attention budget” — Chroma, “Context Rot”; framing from Anthropic’s work on context engineering.
