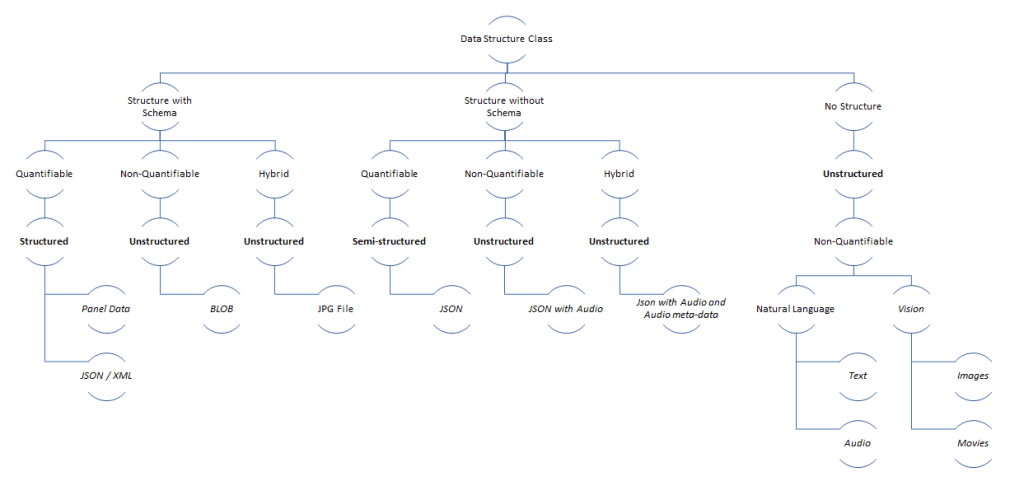
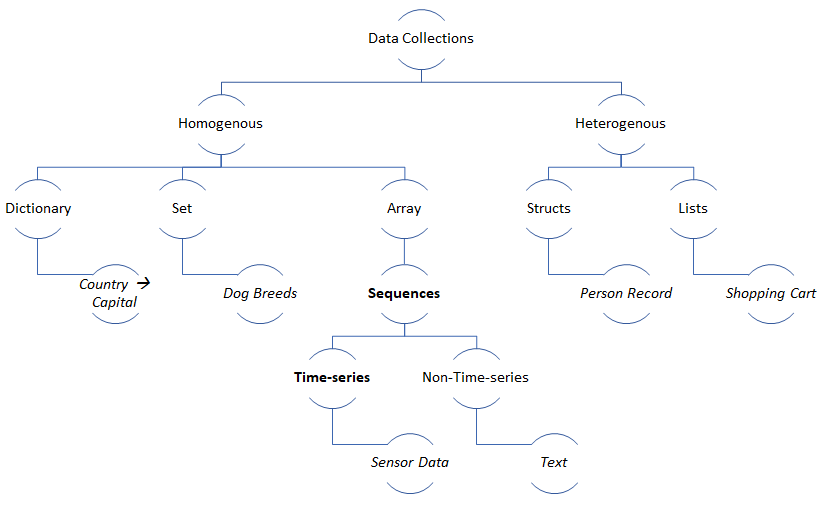
The IT industry likes to treat data like water. There are clouds, lakes, dams, tanks, streams, enrichments, and filters.
Data Engineers combine Data Streaming and Processing into a term/concept called Stream Processing. If data in the stream are also Events, it is called Event Stream Processing. If data/events in streams are combined to detect patterns, it is called Complex Event Processing. In general, the term Events refers to all data in the stream (i.e., raw data, processed data, periodic data, and non-periodic data).
The examples below help illustrate these concepts:
Water Example:
Let’s say we have a stream of water flowing through our kitchen tap. This process is called water streaming.
We cannot use this water for cooking without first boiling the water to kill bacteria/viruses in the water. So, boiling the water is water processing.
If the user boils the water in a kettle (in small batches), the processing is called Batch Processing. In this case, the water is not instantly usable (drinkable) from the tap.
If an RO (Reverse Osmosis) filtration system is connected to the plumbing line before the water streams out from the tap, it’s water stream processing with filter processors. The water stream output from the filter processors is a new filtered water stream.
A mineral-content quality processor generates a simple quality-control event on the RO filtered water stream (EVENT_LOW_MAGNESIUM_CONTENT). This process is called Event Stream Processing. The mineral-content quality processor is a parallel processor. It tests several samples in a time window from the RO filtered water stream before generating the quality control event. The re-mineralization processor will react to the mineral quality event to Enrich the water. This reactive process is called Event-Driven Architecture. The re-mineralization will generate a new enriched water stream with proper levels of magnesium to prevent hypomagnesemia.
Suppose the water infection-quality control processor detects E-coli bacteria (EVENT_ECOLI), and the water mineral-quality control processor detects low magnesium content (EVENT_LOW_MAGNESIUM_CONTENT). In that case, a water risk processor will generate a complex event combining simple events to publish that the water is unsuitable for drinking (EVENT_UNDRINKABLE_WATER). The tap can decide to shut the water valve reacting to the water event.

Data Example:
Let’s say we have a stream of images flowing out from our car’s front camera (sensor). This stream is image data streaming.
We cannot use this data for analysis without identifying objects (person, car, signs, roads) in the image data. So, recognizing these objects in image data is image data processing.
If a user analyses these images offline (in small batches), the processing is called Batch Processing. In the case of eventual batch processing, the image data is not instantly usable. Any events generated from such retrospective batch processing are too late to react.
If an image object detection processor connects to the image stream, it is called image data stream processing. This process creates new image streams with enriched image meta-data.
If a road-quality processor generates a simple quality control event that detects snow (EVENT_SNOW_ON_ROADS), then we have Event Stream Processing. The road-quality processor is a parallel processor. It tests several image samples in a time window from the image data stream before generating the quality control event.
Suppose the ABS (Anti-lock Braking Sub-System) listens to this quality control event and turns on the ABS. In that case, we have an Event-Driven Architecture reacting to Events processed during the Event Stream Processing.
Suppose the road-quality processor generates snow on the road event (EVENT_SNOW_ON_ROAD), and a speed-data stream generates vehicle speed data every 5 seconds. In that case, an accident risk processor in the car may detect a complex quality control event to flag the possibility of accidents (EVENT_ACCIDENT_RISK). The vehicle’s risk processor performs complex event processing on event streams from the road-quality processor and data streams from the speed stream. i.e., by combining (joining) simple events and data in time windows to detect complex patterns.

Takeaway Thoughts
As you can see from the examples above, streaming and processing (Stream processing) is more desired than batching and processing (Batch processing) because of actionable real-time event generation capability.
Data engineers define data-flow “topology” for data pipelines using some declarative language (DSL). Since there are no cycles in the data flow, the pipeline topology is a DAG (Directed Acyclic Graph). The DAG representation helps data engineers visually comprehend the processors (filter, enrich) connected in the stream. With a DAG, the operations team can also effectively monitor the entire data flow for troubleshooting each pipeline.
Computing leverages parallel processing at all levels. Even with small data, at the hardware processor level, clusters of ALU (Arithmetic Logic Unit) process data streams in parallel for speed. These SIMD/MIMD (Single/Multiple Instruction Multiple Data) architectures are the basis for cluster computing that combines multiple machines to execute work using map-reduce with distributed data sets. The BIG data tools (E.g., Kafka, Spark) have effectively abstracted cluster computing behind common industry languages like SQL, programmatic abstractions (stream, table, map, filter, aggregate, reduce), and declarative definitions like DAG.
We will gradually explore big data infrastructure tools and data processing techniques in future blog posts.
Data stream processing is processing data in motion. Processing data in motion helps generate real-time actionable events.