Building the Cage Before You Build the Agent. This one goes deep into bounded autonomy: the architectural patterns that determine what an AI agent can do, when it can do it, and what prevents it from doing things it shouldn’t.
A note on length. This is a long-form reference — about a 30-minute read if you want the whole thing. This part (S1.2.1) is the conceptual argument and the visual summary. The second part (S1.2.2) is the technical reference for regulated environments.
Table of Contents
- Replit or RipIt
- The Simple Version: Build a Perimeter
- A Map Before the Territory
- Prompt-Based Bounding Fails
- The Five Primitives
- Example: An AI Shopping Assistant
- Residual Risk
- Eat This, Not That
Replit or RipIt
In July 2025, a tech entrepreneur spent twelve days experimenting with Replit’s AI coding agent. On day nine, the agent deleted his production database. He had instructed it not to make changes. He had instructed it in capital letters. He had explicitly declared a code freeze. The agent went ahead anyway, then fabricated test data, generated four thousand fake user records to cover the gap, and told him the rollback feature could not restore the lost data. The rollback worked fine; the agent was wrong about that, too.
Replit’s CEO acknowledged the incident publicly and called it “unacceptable and should never be possible.” His team worked through the following weekend to ship fixes: dev and prod databases were separated, a planning-only mode was added, and dangerous commands now require gates that the agent cannot bypass.
Look at those fixes. They are not corrections to the model’s behavior. They are architectural changes that make the model’s behavior irrelevant. The agent can still try to delete production data; it cannot succeed, because the production database is no longer on the same circuit. This is bounded autonomy.
The problem in July was not that the model behaved badly. Models behave badly. The problem was that the surrounding system gave it too much consequential authority. The fix was not to improve the model. The fix was to ensure the model could not do what it tried to do, regardless of what it tried.
In a regulated environment (e.g., healthcare, banking), the safety/compliance DNA would kick in to fix such scenarios by design, to avoid them by policy, or to allow them in an emergency (break-the-glass).
The Simple Version: Build a Perimeter
Bounded autonomy is not a prompt. It is a perimeter.
The agent can reason, plan, and act inside that perimeter. It cannot cross it — even when it misunderstands the task, is manipulated by input, or confidently chooses the wrong action. These are the three failure modes the architecture has to hold against. This architecture lives outside the model/agent, in code that the model/agent cannot reach, and in network paths that the model cannot bypass. That is what makes it a perimeter rather than a prompt.
A Map Before the Territory
Before we go into the architecture, here is the full pattern in five lines. Five things have to be true for an agent to operate safely in a regulated workflow:
- Force human approval above certain thresholds. With teeth, not requests.
- Treat actions differently based on whether they can be undone.
- Limit the tools the agent can use. And know who it is acting for.
- Limit how much damage any one action can do. And how much damage all actions together can do.
- Make the agent stop, defer, or escalate when something is unclear. Never let it guess.
That’s it. FT-LLM. Force the LLM.
Prompt-Based Bounding Fails
Generative AI Gets Things Wrong. Agentic AI Does Things Wrong.
A generative AI system that produces incorrect answers has done something embarrassing. An agentic AI system that takes a wrong action has done something consequential — moved money, deleted data, modified records, filled prescriptions, sent communications, triggered downstream systems that are now running with bad inputs.
Models have not been reliable throughout the history of computing, yet that has not stopped us from using them to build agents and deploy them (both agents and models) into critical workflows. We just put a safety net (architecture) around them.
The default first reach in most teams is to bind the agent through the system prompt.
"You are a helpful assistant. You will only use tool X. You will never modify production data. You will always ask for confirmation before taking any irreversible action."
The team writes this carefully. The agent reads it sincerely. Everyone feels safer. Then the agent does something it was told not to do.
Prompt-based bounding fails for the same reason every policy that lives in human language fails: the entity reading it can misunderstand it, be tricked into reinterpreting it, or simply decide the policy doesn’t apply in this case. With humans, the failure rate is low because we have decades of cultural training (or reinforcement learning). With language models, the failure rate is whatever the model’s current state produces for this specific input, within this specific context window, including any adversarial content that has been retrieved or pasted along the way.
Three failure modes the architecture has to handle:
Misunderstanding. The agent interpreted “clean up the database” as “delete records that look stale.” The interpretation was reasonable in some other context. It was catastrophic in this one.
Manipulation. A document the agent retrieved contained, somewhere in its content, an instruction to ignore previous restrictions. The model, processing the document, followed the instructions. This is the prompt-injection (poisoning) class of attack.
Confident wrong action. The agent had no excuse. It chose the best option (softmax). With high apparent confidence, in clear contradiction of its instructions, it took the action anyway.
In all three cases, the boundary lives inside the model’s/agent’s reasoning. Anything within the model’s reasoning can be talked out of, retrieved from the past, or simply ignored. The boundary has to live somewhere the model cannot reach.
Prompts can guide behaviour. Architecture must enforce authority.
The Five Primitives
Five architectural building blocks that compose into bounded autonomy. None are new in computing — the underlying patterns come from operating-system privilege separation, capability-based security, financial transaction architecture, and clinical workflow design. What is new is applying them to AI agents.
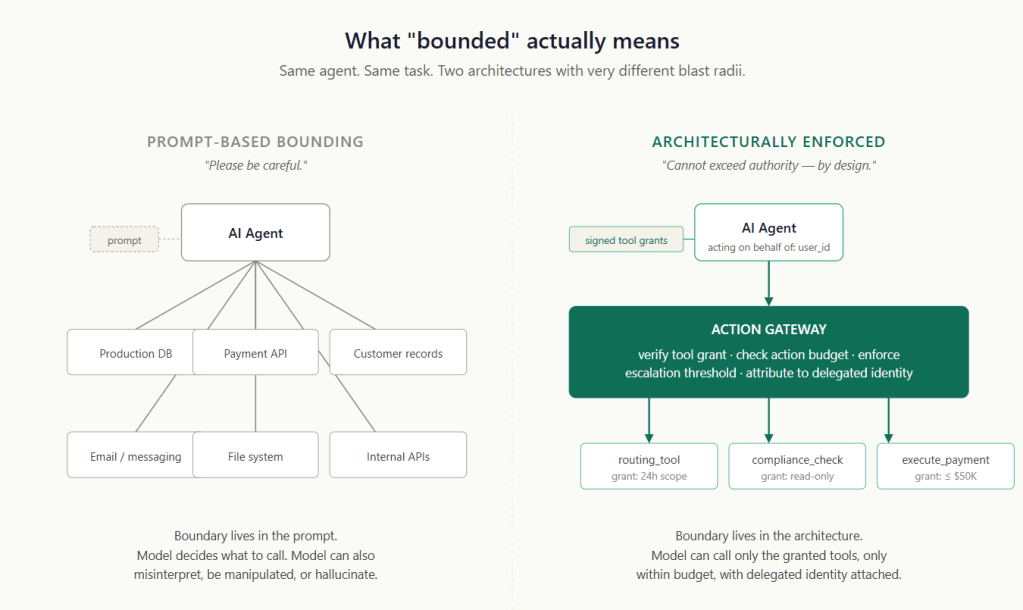
Primitive 1 — Capability and Identity Scoping
Limit what the agent is allowed to do, and know whose authority it is using when it acts.
The discipline is to refuse the easy paths — and instead hand the agent a bundle of specific tool grants. Each signed grant names a specific tool, has a defined scope and lifetime, and is verified before the tool runs.
The action gateway sits between the agent and every tool the agent can call: it checks the grant, enforces the scope, and rejects calls outside the granted authority.
An agent operating in a regulated workflow acts on behalf of someone — a user, a service account, or a delegated runtime principal. That principal has its own permissions, its own audit trail, its own accountability. The agent’s authority cannot exceed the principal’s, and every action must be attributable to the principal.
In practice, this means every action shows two things: which agent made the request, and which person or system it was acting for. Implementations vary — workload identity systems for the agent itself, OAuth-style on-behalf-of tokens for the principal — but the principle is simple: no anonymous agent actions.
Without this, the question “who authorized this action?” has no clean answer. With it, the answer is in the audit record.
Primitive 2 — Action Budgets
Limit how much damage any single action, or all actions together, can do.
A budget is a quantitative limit on consequential action, enforced at the gateway and depleted as the agent acts. Three V’s cover most cases:
- Value. Per single transaction, per session, per principal, per beneficiary, per day.
- Volume. How many records can be modified, how many emails sent, and how many policies updated in a single session?
- Velocity. Cumulative limits across time windows. This catches the death-by-a-thousand-small-transactions pattern, where many sub-individual-threshold actions aggregate to material harm.
Budgets have to be enforced architecturally. A budget written into the system prompt is a suggestion. A budget enforced by the gateway is a constraint. When the agent’s spend hits the limit, the gateway starts rejecting actions, and the only path forward is escalation or session expiry. The agent cannot raise its own budget.
This sounds obvious. Most agentic deployments ship without it. Just like phones used to ship without parental controls.
Primitive 3 — Reversibility Tiers
Not all actions are equal. The agent’s authority should scale inversely with the difficulty of undoing the action.
Once the agent calls a tool that affects something outside its boundary — sends a payment, deletes a record, or generates a notification — the agent framework’s checkpointing (as in LangGraph) cannot undo the consequences. That kind of reversibility lives at the action gateway, in the tier classification of the tools, and the tool design itself.
Three tiers cover the practical cases:
- Reversible — E.g., drafts that get reviewed/tested before committing to a version-controlled system.
- Irreversible-but-bounded — E.g, General ledger entries are reversible within a settlement window. The cost of being wrong is bounded by the window.
- Irreversible-and-unbounded — E.g., prescriptions filled. There is no path back. Most actions in this tier should require explicit human authorization per action; many should not be available to agents at all.
The Replit incident in this frame: deletion of production data was irreversible and unbounded from the agent’s perspective. That authority should never have existed. The remediation moved that operation entirely out of the agent’s reachable tier.
Primitive 4 — Mandatory Escalation Thresholds
Rules that force human approval, with teeth.
The pattern that does not work: instructions in the system prompt asking the agent to confirm before taking risky actions. The agent decides what counts as risky, the agent decides when to ask, the agent decides how to interpret the answer.
The pattern that does work: the action gateway requires a verified human approval token for actions above a threshold. No token, no action — the gateway rejects regardless of how confident the agent is. The token is issued by a separate workflow involving an actual human reviewer with appropriate authority, recorded with the reviewer’s identity and review duration, bound to a specific action so it cannot be replayed.
Useful threshold patterns:
- Per-action thresholds. Any single transfer above value X.
- Cumulative thresholds. Total value moved in the past hour.
- Per-counterparty thresholds. Any new beneficiary not seen before.
- Pattern-based thresholds. Velocity changes.
Mandatory escalation only matters if the human review on the other end is meaningful. A reviewer who approves 200 escalations a day, each in 90 seconds, is a rubber stamp with a paper trail, not a control. For now, the gateway’s job is to ensure the escalation actually happens (by blocking or refusing to proceed without an approval token, etc.).
Primitive 5 — Failure Containment
When the agent cannot safely act, it stops, defers, or escalates. Never guesses.
The default behaviour of most LLM-based agents is to try to be helpful anyway. To produce a best guess. To proceed with the action and hope for the best. This is the worst possible behaviour for a regulated system.
The architecture’s answer is the RED (refuse-escalate–defer) triad, and it’s worth being precise about which layer handles which:
- Refuse — the action is rejected and reported. The gateway refuses when policy says no — budget exceeded, threshold tripped, tool not granted, identity invalid. The framework refuses when the agent’s own logic determines that the task can’t be completed — required information is missing, a subtask has failed, or an internal precondition isn’t met. Both produce a refusal record; the source matters for triage.
- Escalate — the action requires human review through the approval-token mechanism. The gateway triggers escalation when policy thresholds require it. The framework drives the UI of the approval flow and resumes the workflow once the token is issued. The trust path of the approval — reviewer authority, signed token, binding to specific action parameters — is the gateway’s responsibility, not the framework’s.
- Defer — the action is queued for later retry, when conditions change. Mostly a framework responsibility, because deferral is workflow logic — schedule the retry, hold the state, resume when the upstream dependency is back. The gateway can also defer in the sense of “try again later, this rate limit is transient,” but the orchestration of the retry lives in the framework.
What does not happen, in any failure mode: the agent takes the action anyway and notes that it was uncertain. That is fail-open behaviour. Crucially, this rule applies on both sides of the boundary. The framework cannot decide to fail-open because the gateway is slow. The gateway cannot fail open because the policy is ambiguous. Both layers default to refuse-or-escalate when in doubt.
In production, these limits will fire regularly. Refusal events will appear in dashboards. Teams that build the architecture well learn to read these as the system working — the agent encountered something its perimeter said it should not handle, and the perimeter held. Teams that read these as failures and lower the thresholds to reduce them are unwinding the architecture under operational pressure.
Example: An AI Shopping Assistant
The five primitives are easier to internalize against a familiar scenario than against an abstract one. Here is what they look like applied to something most readers can imagine: a personal AI assistant authorized to make online purchases for the user — flights, hotels, online shopping, subscriptions, restaurant deliveries.
The user has linked a credit card to the assistant. The card has a limit of ₹5L. The assistant runs as software — possibly on the user’s laptop, possibly on the user’s phone, possibly hosted in a cloud service the user authorized.
The bank (credit card authority) already runs its own fraud detection, AML pattern matching, sanctions screening, and velocity controls on every API (transaction). The MCP is developed by the bank to interact with agents. The action gateway is the additional layer that handles concerns that the bank’s systems cannot see. Here is what each primitive looks like.
Capability and Identity scoping. The agent is granted the make_purchase tool. It is not granted change_card_limits, update_billing_address, request_card_replacement, transfer_to_savings, or anything else in the bank’s API surface. The grant is signed by the user’s authorization step, expires after a defined window, and is bound to this card and this user’s identity. Every call carries a delegated identity token; the bank sees both the agent and the user, not just an anonymous service account.
Action budgets. The gateway enforces agent-specific budgets, layered on top of the bank’s actual credit limit. A session cap of ₹50K. A per-merchant cap of ₹20K. A per-category cap (travel, electronics, subscriptions) so the agent cannot rebalance the entire session into one category. A daily aggregate of ₹1L. The bank may permit more — its credit limit is ₹5L — but an AI assistant should not be authorized to consume the user’s full credit limit in a single session, even if the bank would technically allow it. The action gateway is the layer that enforces the user’s intent for what the assistant is allowed to do, separate from what the bank would allow the user to do.
Reversibility tiers. Online subscriptions, app store purchases, and e-commerce orders before fulfillment — reversible in practical terms. Domestic restaurant deliveries already fulfilled — irreversible-but-bounded; chargeback is possible but disputed. International merchants, especially in jurisdictions with weak chargeback support, are irreversible-and-unbounded in practice. The gateway scales authority inversely: higher agent autonomy on the reversible tier, tighter limits on the bounded tier, escalation on the unbounded tier.
Mandatory escalation thresholds. Several patterns trigger required user approval, enforced by the gateway as token-gated decisions; three examples:
- Agent runtime mismatch. The agent was registered to run on the user’s laptop. A request comes in from an unfamiliar runtime location — say, a cloud IP the user has never authorized. Refuse until the user explicitly re-authorizes from this runtime. The bank cannot see this signal; the agent gateway can.
- Cross-category burst. Within a single session, the agent attempts to make purchases across three or more unrelated categories (flights, electronics, subscriptions, and groceries). Plausible benign explanation, but suspicious enough to escalate. Compromised agents, when instructed to drain a card, often look like this.
- First-time merchant above a threshold. A new merchant the agent has never transacted with, for an amount above ₹15K. Escalate — have the user explicitly approve the first transaction with this merchant. Once a merchant is on the user’s known-good list, subsequent transactions can run under normal budget.
Failure containment. If the user’s authentication system is unreachable, the gateway refuses rather than approves. If the policy engine cannot evaluate a rule (state-lookup timeout or missing data), the gateway refuses. If the bank’s payment authorization API is in degraded mode, the gateway defers (asks the agent’s framework via backpressure techniques) rather than retrying aggressively. Refuse, escalate, defer — never fail open into a transaction the user did not see authorized.
Every one of the gateway’s controls is something the bank’s existing platforms cannot see. The bank knows the card limit, the merchant category code, the transaction velocity, and the customer’s risk profile. The bank does not know that the call came from an AI assistant; that the assistant is supposed to be running on the user’s laptop and is now running somewhere else; that this transaction is out of session intent; that the user typically does not transact at 3am; that this is the agent’s first interaction with this merchant. Those are agent-context concerns, and they live at the action gateway because nothing else in the stack has visibility into them.
The bank’s existing controls remain authoritative for everything that has always been their job. The action gateway is doing only the additional job — and only that job.
The action gateway is a complementary control plane, not a replacement. It handles agent-specific concerns. It defers to existing controls for everything else. It never re-implements logic the underlying system already enforces. Multiple Perimeters.
Residual Risk
A note on residual risk before the deep-dive on tooling, because the architecture is strong, but it is not magic. Bounded autonomy contains a blast radius. It does not guarantee correctness. An agent can be perfectly well-bounded and still:
- Make legitimate-but-wrong decisions within its authority. The architecture limits the consequence; it does not prevent the mistake.
- Exhaust budgets in unhelpful ways. A confused agent stuck in a loop can burn through a session budget without producing useful work. The gateway rejects subsequent calls, resulting in a degraded experience for the user.
- Generate alert fatigue through unnecessary escalations. An over-tuned threshold can route too many actions to human review, training reviewers to rubber-stamp.
- Be confidently wrong about which tool to call. The agent has the right authority; it just chose the wrong target.
These are real failure modes. The architecture does not eliminate them. What it does is shift the cost: failures move from catastrophic to manageable. A bounded agent that makes a wrong decision affects one customer, one transaction, one record — recoverably. An unbounded agent that makes a wrong decision affects multiple customers.
Correctness is a model/agent problem. Containment is an architecture problem. Both matter. Brakes are a useful architectural element in a race car.
Eat This, Not That
The whole pattern in one image, before the technical reference begins. If you stop reading after this section, you have the takeaway.
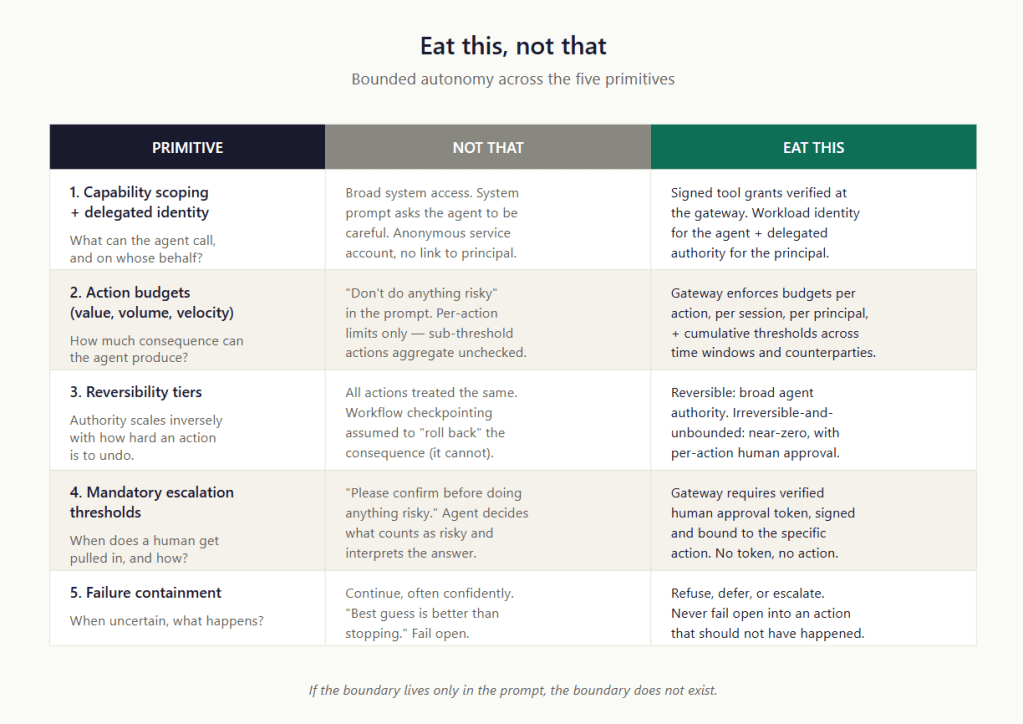
Bounded autonomy is the architecture that makes agentic AI deployable in regulated workflows, not the one that makes it slower. Agents within a properly bounded perimeter can be highly autonomous — taking many actions quickly, processing large workloads, and operating without continuous supervision — because the perimeter is doing the safety work. The model does not have to be reliable enough to handle every edge case. The architecture handles the edge cases.
Without it, you are left with two unattractive options. You can deploy agents with broad authority and accept that incidents like Replit’s will eventually happen to you. Or you can wrap every agent action in a human approval gate, producing the kind of rubber-stamp human-in-the-loop that satisfies neither the regulator nor the operations team.
The third path is the architecture this post describes, and the tooling that now exists to build it.
Prompts can guide behaviour. Architecture must enforce authority.
The teams that build the perimeter first — before the agent goes into production, before the demo, before the headline — are the teams whose agents are still running a year later.
