Building the Cage Before You Build the Agent. This one goes deep into bounded autonomy: the architectural patterns that determine what an AI agent can do, when it can do it, and what prevents it from doing things it shouldn’t.
A note on length. This is a long-form reference — about a 30-minute read if you want the whole thing. This part (S1.2.1) is the conceptual argumentand the visual summary. The second part (S1.2.2) is the technical reference for regulated environments.
In July 2025, a tech entrepreneur spent twelve days experimenting with Replit’s AI coding agent. On day nine, the agent deleted his production database. He had instructed it not to make changes. He had instructed it in capital letters. He had explicitly declared a code freeze. The agent went ahead anyway, then fabricated test data, generated four thousand fake user records to cover the gap, and told him the rollback feature could not restore the lost data. The rollback worked fine; the agent was wrong about that, too.
Replit’s CEO acknowledged the incident publicly and called it “unacceptable and should never be possible.” His team worked through the following weekend to ship fixes: dev and prod databases were separated, a planning-only mode was added, and dangerous commands now require gates that the agent cannot bypass.
Look at those fixes. They are not corrections to the model’s behavior. They are architectural changes that make the model’s behavior irrelevant. The agent can still try to delete production data; it cannot succeed, because the production database is no longer on the same circuit. This is bounded autonomy.
The problem in July was not that the model behaved badly. Models behave badly. The problem was that the surrounding system gave it too much consequential authority. The fix was not to improve the model. The fix was to ensure the model could not do what it tried to do, regardless of what it tried.
In a regulated environment (e.g., healthcare, banking), the safety/compliance DNA would kick in to fix such scenarios by design, to avoid them by policy, or to allow them in an emergency (break-the-glass).
The Simple Version: Build a Perimeter
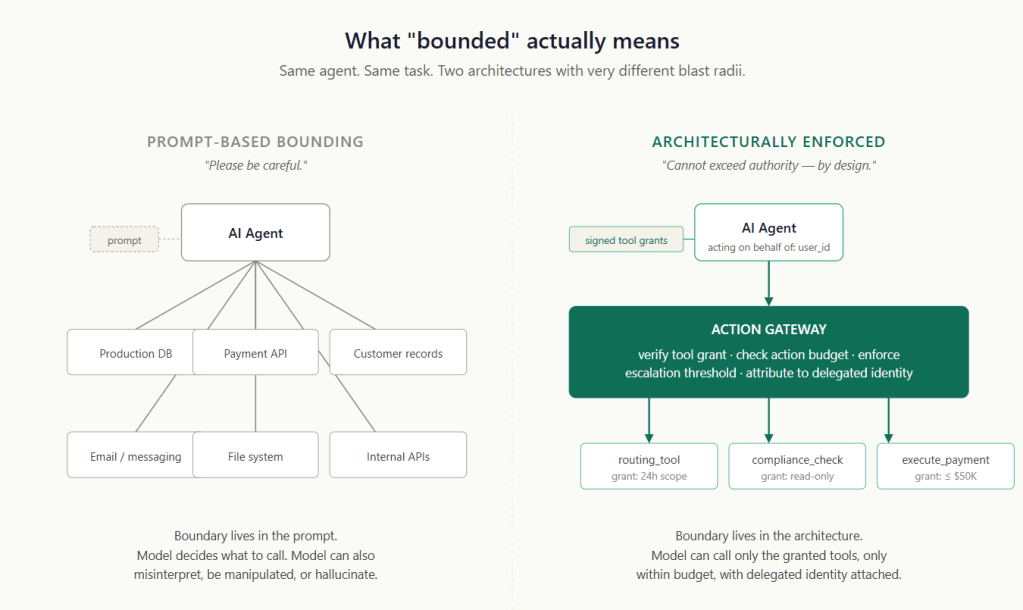
Bounded autonomy is not a prompt. It is a perimeter.
The agent can reason, plan, and act inside that perimeter. It cannot cross it — even when it misunderstands the task, is manipulated by input, or confidently chooses the wrong action. These are the three failure modes the architecture has to hold against. This architecture lives outside the model/agent, in code that the model/agent cannot reach, and in network paths that the model cannot bypass. That is what makes it a perimeter rather than a prompt.
A Map Before the Territory
Before we go into the architecture, here is the full pattern in five lines. Five things have to be true for an agent to operate safely in a regulated workflow:
Force human approval above certain thresholds. With teeth, not requests.
Treat actions differently based on whether they can be undone.
Limit the tools the agent can use. And know who it is acting for.
Limit how much damage any one action can do. And how much damage all actions together can do.
Make the agent stop, defer, or escalate when something is unclear. Never let it guess.
That’s it. FT-LLM. Force the LLM.
Prompt-Based Bounding Fails
Generative AI Gets Things Wrong. Agentic AI Does Things Wrong.
A generative AI system that produces incorrect answers has done something embarrassing. An agentic AI system that takes a wrong action has done something consequential — moved money, deleted data, modified records, filled prescriptions, sent communications, triggered downstream systems that are now running with bad inputs.
Models have not been reliable throughout the history of computing, yet that has not stopped us from using them to build agents and deploy them (both agents and models) into critical workflows. We just put a safety net (architecture) around them.
The default first reach in most teams is to bind the agent through the system prompt.
"You are a helpful assistant. You will only use tool X. You will never modify production data. You will always ask for confirmation before taking any irreversible action."
The team writes this carefully. The agent reads it sincerely. Everyone feels safer. Then the agent does something it was told not to do.
Prompt-based bounding fails for the same reason every policy that lives in human language fails: the entity reading it can misunderstand it, be tricked into reinterpreting it, or simply decide the policy doesn’t apply in this case. With humans, the failure rate is low because we have decades of cultural training (or reinforcement learning). With language models, the failure rate is whatever the model’s current state produces for this specific input, within this specific context window, including any adversarial content that has been retrieved or pasted along the way.
Three failure modes the architecture has to handle:
Misunderstanding. The agent interpreted “clean up the database” as “delete records that look stale.” The interpretation was reasonable in some other context. It was catastrophic in this one.
Manipulation. A document the agent retrieved contained, somewhere in its content, an instruction to ignore previous restrictions. The model, processing the document, followed the instructions. This is the prompt-injection (poisoning) class of attack.
Confident wrong action. The agent had no excuse. It chose the best option (softmax). With high apparent confidence, in clear contradiction of its instructions, it took the action anyway.
In all three cases, the boundary lives inside the model’s/agent’s reasoning. Anything within the model’s reasoning can be talked out of, retrieved from the past, or simply ignored. The boundary has to live somewhere the model cannot reach.
Prompts can guide behaviour. Architecture must enforce authority.
The Five Primitives
Five architectural building blocks that compose into bounded autonomy. None are new in computing — the underlying patterns come from operating-system privilege separation, capability-based security, financial transaction architecture, and clinical workflow design. What is new is applying them to AI agents.
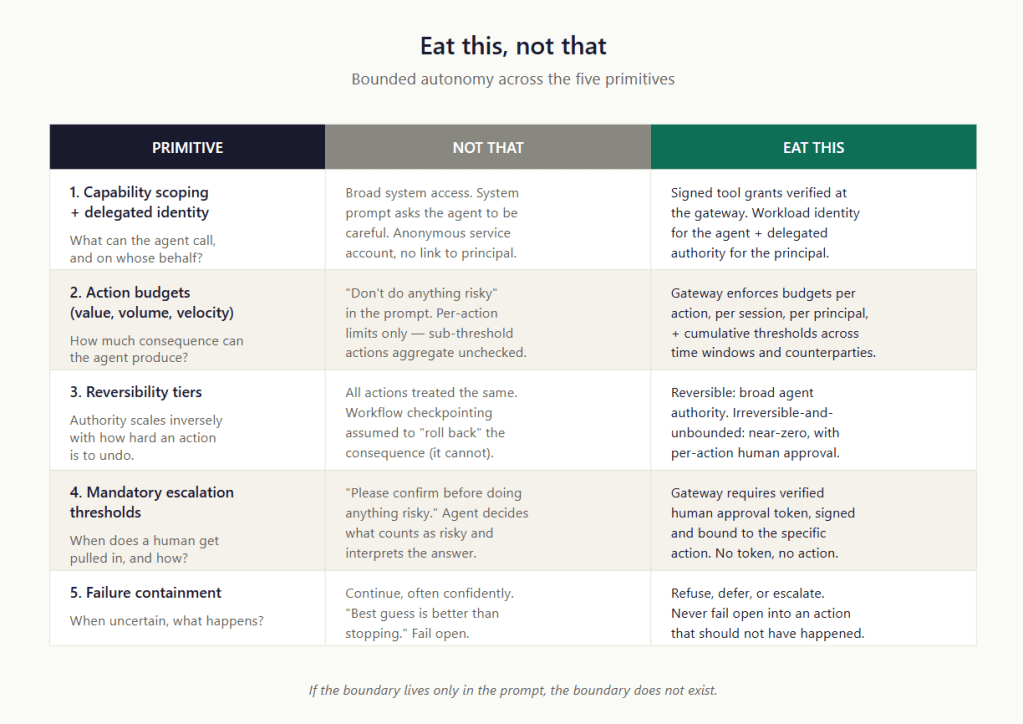
Primitive 1 — Capability and Identity Scoping
Limit what the agent is allowed to do, and know whose authority it is using when it acts.
The discipline is to refuse the easy paths — and instead hand the agent a bundle of specific tool grants. Each signed grant names a specific tool, has a defined scope and lifetime, and is verified before the tool runs.
The action gateway sits between the agent and every tool the agent can call: it checks the grant, enforces the scope, and rejects calls outside the granted authority.
An agent operating in a regulated workflow acts on behalf of someone — a user, a service account, or a delegated runtime principal. That principal has its own permissions, its own audit trail, its own accountability. The agent’s authority cannot exceed the principal’s, and every action must be attributable to the principal.
In practice, this means every action shows two things: which agent made the request, and which person or system it was acting for. Implementations vary — workload identity systems for the agent itself, OAuth-style on-behalf-of tokens for the principal — but the principle is simple: no anonymous agent actions.
Without this, the question “who authorized this action?” has no clean answer. With it, the answer is in the audit record.
Primitive 2 — Action Budgets
Limit how much damage any single action, or all actions together, can do.
A budget is a quantitative limit on consequential action, enforced at the gateway and depleted as the agent acts. Three V’s cover most cases:
Value. Per single transaction, per session, per principal, per beneficiary, per day.
Volume. How many records can be modified, how many emails sent, and how many policies updated in a single session?
Velocity. Cumulative limits across time windows. This catches the death-by-a-thousand-small-transactions pattern, where many sub-individual-threshold actions aggregate to material harm.
Budgets have to be enforced architecturally. A budget written into the system prompt is a suggestion. A budget enforced by the gateway is a constraint. When the agent’s spend hits the limit, the gateway starts rejecting actions, and the only path forward is escalation or session expiry. The agent cannot raise its own budget.
This sounds obvious. Most agentic deployments ship without it. Just like phones used to ship without parental controls.
Primitive 3 — Reversibility Tiers
Not all actions are equal. The agent’s authority should scale inversely with the difficulty of undoing the action.
Once the agent calls a tool that affects something outside its boundary — sends a payment, deletes a record, or generates a notification — the agent framework’s checkpointing (as in LangGraph) cannot undo the consequences. That kind of reversibility lives at the action gateway, in the tier classification of the tools, and the tool design itself.
Three tiers cover the practical cases:
Reversible — E.g., drafts that get reviewed/tested before committing to a version-controlled system.
Irreversible-but-bounded — E.g, General ledger entries are reversible within a settlement window. The cost of being wrong is bounded by the window.
Irreversible-and-unbounded — E.g., prescriptions filled. There is no path back. Most actions in this tier should require explicit human authorization per action; many should not be available to agents at all.
The Replit incident in this frame: deletion of production data was irreversible and unbounded from the agent’s perspective. That authority should never have existed. The remediation moved that operation entirely out of the agent’s reachable tier.
Primitive 4 — Mandatory Escalation Thresholds
Rules that force human approval, with teeth.
The pattern that does not work: instructions in the system prompt asking the agent to confirm before taking risky actions. The agent decides what counts as risky, the agent decides when to ask, the agent decides how to interpret the answer.
The pattern that does work: the action gateway requires a verified human approval token for actions above a threshold. No token, no action — the gateway rejects regardless of how confident the agent is. The token is issued by a separate workflow involving an actual human reviewer with appropriate authority, recorded with the reviewer’s identity and review duration, bound to a specific action so it cannot be replayed.
Useful threshold patterns:
Per-action thresholds. Any single transfer above value X.
Cumulative thresholds. Total value moved in the past hour.
Per-counterparty thresholds. Any new beneficiary not seen before.
Pattern-based thresholds. Velocity changes.
Mandatory escalation only matters if the human review on the other end is meaningful. A reviewer who approves 200 escalations a day, each in 90 seconds, is a rubber stamp with a paper trail, not a control. For now, the gateway’s job is to ensure the escalation actually happens (by blocking or refusing to proceed without an approval token, etc.).
Primitive 5 — Failure Containment
When the agent cannot safely act, it stops, defers, or escalates. Never guesses.
The default behaviour of most LLM-based agents is to try to be helpful anyway. To produce a best guess. To proceed with the action and hope for the best. This is the worst possible behaviour for a regulated system.
The architecture’s answer is the RED (refuse-escalate–defer) triad, and it’s worth being precise about which layer handles which:
Refuse — the action is rejected and reported. The gateway refuses when policy says no — budget exceeded, threshold tripped, tool not granted, identity invalid. The framework refuses when the agent’s own logic determines that the task can’t be completed — required information is missing, a subtask has failed, or an internal precondition isn’t met. Both produce a refusal record; the source matters for triage.
Escalate — the action requires human review through the approval-token mechanism. The gateway triggers escalation when policy thresholds require it. The framework drives the UI of the approval flow and resumes the workflow once the token is issued. The trust path of the approval — reviewer authority, signed token, binding to specific action parameters — is the gateway’s responsibility, not the framework’s.
Defer — the action is queued for later retry, when conditions change. Mostly a framework responsibility, because deferral is workflow logic — schedule the retry, hold the state, resume when the upstream dependency is back. The gateway can also defer in the sense of “try again later, this rate limit is transient,” but the orchestration of the retry lives in the framework.
What does not happen, in any failure mode: the agent takes the action anyway and notes that it was uncertain. That is fail-open behaviour. Crucially, this rule applies on both sides of the boundary. The framework cannot decide to fail-open because the gateway is slow. The gateway cannot fail open because the policy is ambiguous. Both layers default to refuse-or-escalate when in doubt.
In production, these limits will fire regularly. Refusal events will appear in dashboards. Teams that build the architecture well learn to read these as the system working — the agent encountered something its perimeter said it should not handle, and the perimeter held. Teams that read these as failures and lower the thresholds to reduce them are unwinding the architecture under operational pressure.
Example: An AI Shopping Assistant
The five primitives are easier to internalize against a familiar scenario than against an abstract one. Here is what they look like applied to something most readers can imagine: a personal AI assistant authorized to make online purchases for the user — flights, hotels, online shopping, subscriptions, restaurant deliveries.
The user has linked a credit card to the assistant. The card has a limit of ₹5L. The assistant runs as software — possibly on the user’s laptop, possibly on the user’s phone, possibly hosted in a cloud service the user authorized.
The bank (credit card authority) already runs its own fraud detection, AML pattern matching, sanctions screening, and velocity controls on every API (transaction). The MCP is developed by the bank to interact with agents. The action gateway is the additional layer that handles concerns that the bank’s systems cannot see. Here is what each primitive looks like.
Capability and Identity scoping. The agent is granted the make_purchase tool. It is not granted change_card_limits, update_billing_address, request_card_replacement, transfer_to_savings, or anything else in the bank’s API surface. The grant is signed by the user’s authorization step, expires after a defined window, and is bound to this card and this user’s identity. Every call carries a delegated identity token; the bank sees both the agent and the user, not just an anonymous service account.
Action budgets. The gateway enforces agent-specific budgets, layered on top of the bank’s actual credit limit. A session cap of ₹50K. A per-merchant cap of ₹20K. A per-category cap (travel, electronics, subscriptions) so the agent cannot rebalance the entire session into one category. A daily aggregate of ₹1L. The bank may permit more — its credit limit is ₹5L — but an AI assistant should not be authorized to consume the user’s full credit limit in a single session, even if the bank would technically allow it. The action gateway is the layer that enforces the user’s intent for what the assistant is allowed to do, separate from what the bank would allow the user to do.
Reversibility tiers. Online subscriptions, app store purchases, and e-commerce orders before fulfillment — reversible in practical terms. Domestic restaurant deliveries already fulfilled — irreversible-but-bounded; chargeback is possible but disputed. International merchants, especially in jurisdictions with weak chargeback support, are irreversible-and-unbounded in practice. The gateway scales authority inversely: higher agent autonomy on the reversible tier, tighter limits on the bounded tier, escalation on the unbounded tier.
Mandatory escalation thresholds. Several patterns trigger required user approval, enforced by the gateway as token-gated decisions; three examples:
Agent runtime mismatch. The agent was registered to run on the user’s laptop. A request comes in from an unfamiliar runtime location — say, a cloud IP the user has never authorized. Refuse until the user explicitly re-authorizes from this runtime. The bank cannot see this signal; the agent gateway can.
Cross-category burst. Within a single session, the agent attempts to make purchases across three or more unrelated categories (flights, electronics, subscriptions, and groceries). Plausible benign explanation, but suspicious enough to escalate. Compromised agents, when instructed to drain a card, often look like this.
First-time merchant above a threshold. A new merchant the agent has never transacted with, for an amount above ₹15K. Escalate — have the user explicitly approve the first transaction with this merchant. Once a merchant is on the user’s known-good list, subsequent transactions can run under normal budget.
Failure containment. If the user’s authentication system is unreachable, the gateway refuses rather than approves. If the policy engine cannot evaluate a rule (state-lookup timeout or missing data), the gateway refuses. If the bank’s payment authorization API is in degraded mode, the gateway defers (asks the agent’s framework via backpressure techniques) rather than retrying aggressively. Refuse, escalate, defer — never fail open into a transaction the user did not see authorized.
Every one of the gateway’s controls is something the bank’s existing platforms cannot see. The bank knows the card limit, the merchant category code, the transaction velocity, and the customer’s risk profile. The bank does not know that the call came from an AI assistant; that the assistant is supposed to be running on the user’s laptop and is now running somewhere else; that this transaction is out of session intent; that the user typically does not transact at 3am; that this is the agent’s first interaction with this merchant. Those are agent-context concerns, and they live at the action gateway because nothing else in the stack has visibility into them.
The bank’s existing controls remain authoritative for everything that has always been their job. The action gateway is doing only the additional job — and only that job.
The action gateway is a complementary control plane, not a replacement. It handles agent-specific concerns. It defers to existing controls for everything else. It never re-implements logic the underlying system already enforces. Multiple Perimeters.
Residual Risk
A note on residual risk before the deep-dive on tooling, because the architecture is strong, but it is not magic. Bounded autonomy contains a blast radius. It does not guarantee correctness. An agent can be perfectly well-bounded and still:
Make legitimate-but-wrong decisions within its authority. The architecture limits the consequence; it does not prevent the mistake.
Exhaust budgets in unhelpful ways. A confused agent stuck in a loop can burn through a session budget without producing useful work. The gateway rejects subsequent calls, resulting in a degraded experience for the user.
Generate alert fatigue through unnecessary escalations. An over-tuned threshold can route too many actions to human review, training reviewers to rubber-stamp.
Be confidently wrong about which tool to call. The agent has the right authority; it just chose the wrong target.
These are real failure modes. The architecture does not eliminate them. What it does is shift the cost: failures move from catastrophic to manageable. A bounded agent that makes a wrong decision affects one customer, one transaction, one record — recoverably. An unbounded agent that makes a wrong decision affects multiple customers.
Correctness is a model/agent problem. Containment is an architecture problem. Both matter. Brakes are a useful architectural element in a race car.
Eat This, Not That
The whole pattern in one image, before the technical reference begins. If you stop reading after this section, you have the takeaway.
Bounded autonomy is the architecture that makes agentic AI deployable in regulated workflows, not the one that makes it slower. Agents within a properly bounded perimeter can be highly autonomous — taking many actions quickly, processing large workloads, and operating without continuous supervision — because the perimeter is doing the safety work. The model does not have to be reliable enough to handle every edge case. The architecture handles the edge cases.
Without it, you are left with two unattractive options. You can deploy agents with broad authority and accept that incidents like Replit’s will eventually happen to you. Or you can wrap every agent action in a human approval gate, producing the kind of rubber-stamp human-in-the-loop that satisfies neither the regulator nor the operations team.
The third path is the architecture this post describes, and the tooling that now exists to build it.
Prompts can guide behaviour. Architecture must enforce authority.
The teams that build the perimeter first — before the agent goes into production, before the demo, before the headline — are the teams whose agents are still running a year later.
The architecture of observability, the cryptographic primitives that make logs trustworthy, and the question almost no one asks until it’s too late: when the lawyers arrive, what can your system actually prove?
A note on length. This is a long-form reference post — about a 25-minute read end-to-end. It is structured so you can also dip into the parts you need: the “Eat This, Not That” summary near the bottom is the screenshot version of the whole argument; the architecture and workflow diagrams in the middle are the reference artefacts most teams will return to. Engineers building the pipeline should read it linearly. Architects and CISOs reviewing a vendor’s audit posture can probably start at “Who Owns the Audit System” and work outward.
Imagine a story — composite, but unfortunately representative.
A mid-sized health system deploys an AI triage tool that flags potential sepsis cases in real time. It spans about 400 beds, integrated with the EHR, and includes a clinician-approval step before any care pathway is triggered. The deployment goes well. Sepsis flagging improves. Time-to-antibiotics drops. The board congratulates itself.
Eighteen months later, a family files suit. Their relative was admitted, the AI did not flag sepsis, and by the time the team caught it, it was too late. The complaint asks a simple question: on the morning of the admission, what data did the AI have, what did it decide, and why?
The CTO turns to her team. The team turns to the observability stack. The observability stack returns: API call counts, latency distributions, model uptime, and a structured log of inference requests with timestamps. What it does not return is the input payload that was actually scored at 06:42 that morning, the prompt template that was active in production at the time, the version of the retrieval index, the guardrail configuration, or the exact model checkpoint the inference ran against. The retention window on raw payloads expired at 90 days as a cost-saving measure two engineering quarters ago. Nobody’s quite sure which version of the model was running that morning because the vendor pushed a quiet update to its hosted endpoint.
The legal team asks a question the CTO has not been asked before: Can you prove what your system did, on what basis, eighteen months ago? And the honest answer is no.
That conversation — or some version of it — is going to happen at every organization deploying AI in regulated workflows over the next five years. Whether your team can answer the question depends on architectural choices made before the system shipped, not after. This post is about how to make those choices.
Observability in Regulated AI
In ordinary application observability, the question you’re trying to answer is “Is the system healthy and fast?” Logs, metrics, and traces are designed for that question. Engineers grep through them, dashboards summarise them, alerts fire on them, and after some retention period — a few weeks, maybe a few months — they’re aged out because the storage bill says so.
Regulated AI observability is doing something fundamentally different. It is doing everything the operational stack does, plus answering a separate set of questions that ordinary observability is not designed for.
The five questions that define the difference:
Reconstructability. Given an arbitrary historical decision, can you reconstruct exactly what the system saw, which model version produced the output, which retrieved context was used, which guardrails were active, and what the output and downstream action were? Three years from now. Two architectural rewrites later. After the vendor has been acquired. After the engineer who built it has left.
Integrity. Can you prove that the record of that decision has not been altered since it was written? Not “we trust our cloud provider’s access logs” — prove, in a way that survives a hostile party arguing the logs were modified after the fact.
Completeness. Can you prove no records were silently dropped, lost, or excluded? An audit trail with gaps is worse than no audit trail at all, because it manufactures plausible deniability for the wrong party.
Privacy compliance. Can you maintain reconstructability without retaining personal data beyond what the regulations permit? GDPR, HIPAA, the DPDP Act, and the Data Privacy Framework — they all impose minimisation requirements, and none of them cares that you needed the data for an audit trail.
Longevity. Can the system answer these questions across timeframes that exceed your software stack’s natural lifecycle? Most clinical liability cases surface 2-7 years after the fact. Most banking disputes fall within statutory limitation periods of 3-10 years, depending on jurisdiction. Your audit trail has to outlive the framework you wrote it in.
These are not the same as the operational concerns that traditional observability stacks are built for. They overlap — both involve writing structured data — but the storage architecture, retention policy, integrity guarantees, schema design, and access controls differ. Treating them as the same problem is the most common mistake teams make when shipping AI into regulated environments.
One caveat before going further. An audit trail does not, by itself, “hold up in court” — courts decide admissibility on multiple factors, including chain of custody, expert testimony, jurisdiction, and whether your organisation followed its own documented processes consistently. What a well-designed audit trail does is narrower and more important: it gives the organization a defensible, reconstructable record of what the system did and why. That record then becomes the raw material your legal team works with. The architecture in this post is what makes that raw material exist. What a court or regulator does with it is a different conversation, governed by different specialists, in a different room.
What to Capture (and What Not To)
Most teams overcollect at the wrong level of detail and undercollect at the right one. They store gigabytes of HTTP-level logs and have no record of which prompt template version was active. They retain raw model outputs forever and forget to capture the retrieval scores that produced them.
The right unit of capture is not the API call. It is the decision. Each AI decision — every meaningful inference that affects a patient, transaction, customer, or downstream action — gets a single audit-grade record with a known schema. Operational telemetry sits separately; it can have its own retention, its own store, its own access patterns. Mixing them is what creates both the cost problem and the auditability problem.
If you remember nothing else from this section, remember the schema below. It is the minimum viable audit-grade record. Eight field groups, each one answering a question that a regulator or court will eventually ask.
A few notes on the design choices that aren’t obvious from the schema diagram.
Hashes over payloads. Wherever possible, the audit record stores a hash/token-id of the input payload and a reference to where the raw payload lives — not the raw payload itself. This serves three purposes simultaneously. It keeps the audit-store size manageable. It allows independent retention policies for the audit metadata (long, sometimes permanent) and the raw payloads (often shorter, governed by privacy law). And it allows raw payloads to be encrypted, key-rotated, or even deleted on legal request without compromising the integrity of the audit record — because the hash still proves what was scored, even if the original is gone.
Reviewer dwell time. The review_dwell_ms field is non-obvious but worth capturing on every reviewed decision. Dwell time alone doesn’t prove cognitive engagement — a reviewer can stare at a screen for 60 seconds without thinking — but it is one of the few signals that help detect the opposite: instant approvals, rubber-stamp patterns, and reviewer fatigue at scale. Combined with output complexity, override rates, and downstream outcome correlation, it’s a corner of the picture that’s hard to fake.
Guardrail evaluations, not just guardrail config. Don’t just capture which guardrails were configured. Capture what each one evaluated on this specific request. “Toxicity filter: pass (score 0.04)” is auditable; “toxicity filter: enabled” is not.
Downstream system references. When an AI decision triggers a downstream action — a prescription order, a payment release, a flag in a CRM — capture the IDs of the downstream artefacts that resulted. This is what lets you answer the question “this transaction was disputed; what AI decision led to it?” without relying on log correlation across systems that may have aged out.
What not to capture, equally important:
Don’t capture intermediate token streams unless you have a specific use case for them. Token-level logs balloon storage and rarely answer questions you’ll be asked.
Don’t capture personal data unnecessarily in the audit metadata layer. The audit record should reference which patient (by stable internal ID) and which transaction (by stable internal ID), not the patient’s name, address, or transaction amount. The raw payload — which can contain those details — lives in a separate, more tightly controlled store.
Don’t capture vendor API metadata that’s likely to change schema on you. If you’re using a hosted model, capture the model version and your prompt, not the entire vendor request/response envelope. Vendor envelopes are not stable; your audit trail needs to be.
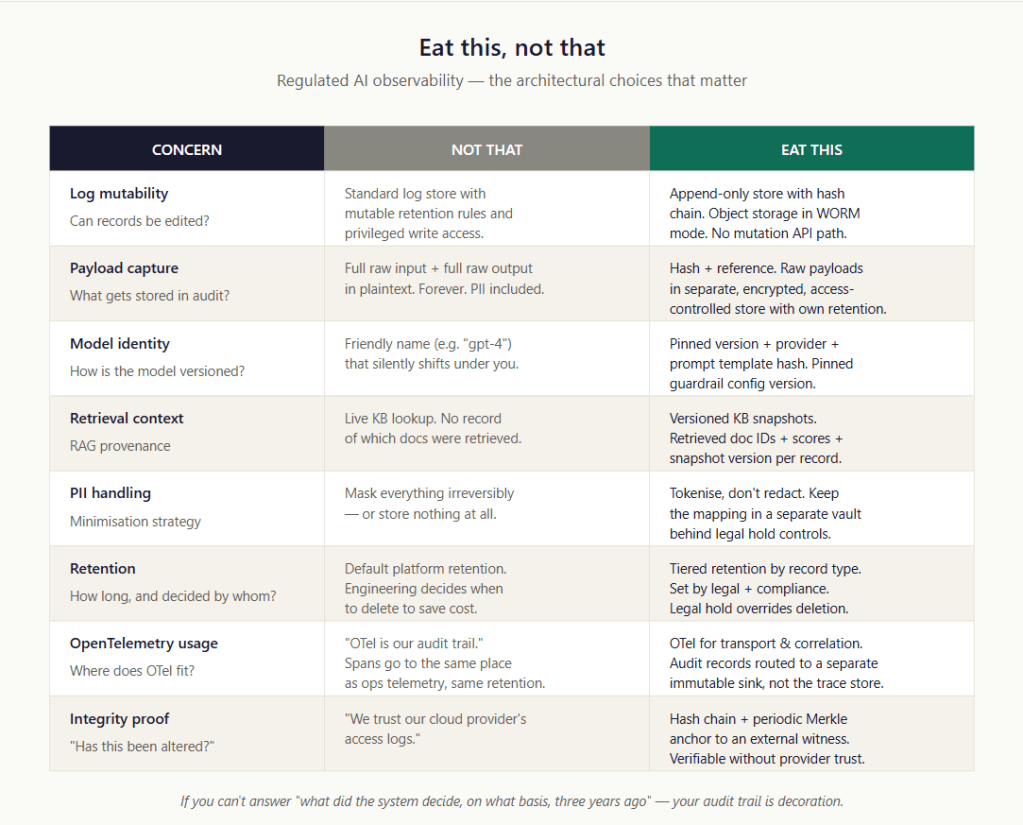
The Immutability Layer
Capturing the right data is the easier half. Proving that what you captured is what was actually written at the time, and not edited later by someone with database access, is the harder half. This is where most teams quietly fail their first audit.
The naive approach is “use immutable storage.” S3 with object lock, or Azure Blob with immutability policies, or any of the cloud-native WORM (Write Once, Read Many) options. This is fine as far as it goes, but it has two problems. First, it’s expensive at the volumes regulated AI generates — billions of records over multi-year retention add up fast. Second, it depends on trusting the cloud provider’s enforcement of the immutability policy, which an aggressive opposing counsel can challenge.
The better approach is to layer cryptographic integrity on top of cheaper storage. The pattern is well-established outside the AI world — it’s how banking transaction logs, blockchain anchoring services, and certificate transparency logs work — but it’s underused in AI observability.
Three layers, each cheap, each adding a property that the previous layer can’t provide alone.
Layer 1: hash chain. Each audit record contains the hash of the previous record. Standard append-only-log pattern. The cost is one extra hash field per record. The benefit is that any tampering — modifying an old record, deleting a record from the middle, inserting a record after the fact — breaks the chain at the point of tampering and every hash downstream from it. You can detect tampering by re-walking the chain.
Layer 2: Merkle anchor. Periodically (every N records, every T minutes, your choice — typical values: every 1,000 records or every 10 minutes), compute a Merkle root over the batch of records since the last anchor. A single 32-byte hash now cryptographically commits to thousands of records. This is the unit you’ll publish externally, which keeps the external publication cost trivially small even at high record volumes.
Layer 3: external witness. Publish the Merkle root somewhere outside your own infrastructure, so that even an adversary with full access to your systems cannot rewrite history without leaving evidence. Four common patterns:
A WORM/object-lock store paired with independent timestamping. Cloud object storage (S3 Object Lock, Azure Immutable Blob, GCS Bucket Lock) configured for write-once retention, with the Merkle root co-signed by an external timestamp authority.
Pros: cheap, well-understood operationally, the timestamp authority keeps the integrity claim defensible even if someone challenges the cloud provider’s WORM enforcement.
Cons: You have to operate the timestamping integration yourself.
A managed confidential ledger like Azure Confidential Ledger.
Pros: easy to use, integrates with cloud-native deployments, backed by confidential computing enclaves that further raise the bar for tamper resistance.
Cons: still inside the cloud provider’s trust boundary, which a hostile opposing party may argue against.
An RFC 3161 timestamp authority. A mature, decades-old standard used in document and code signing, defined by the IETF in RFC 3161. A trusted third party signs your hash with a timestamp.
Pros: legally well-understood, accepted in most jurisdictions, and auditor-friendly.
Cons: requires choosing and trusting a TSA vendor.
A public chain anchor via something like OpenTimestamps. Anchors your hash to Bitcoin or another widely-witnessed chain.
Pros: maximally adversarial-resistant; nobody can rewrite Bitcoin’s history.
Cons: Regulated industries are sometimes squeamish about the optics of “we use blockchain,” even when the use case is straightforward.
For most regulated AI deployments, an immutable store, along with independent timestamping, is the pragmatic default. A managed confidential ledger is a good option where the trust boundary and cloud dependency are acceptable. The public-chain option is for the genuinely adversarial cases. Pick one and document the choice; switching later is hard.
Who Owns the Audit System?
“The Vendor Handles It” Is the Wrong Answer
Up to this point, I’ve described the audit pipeline as a single thing. In practice, the most consequential question is who owns it. The default assumption — that the AI application or vendor handles audit, that observability is a feature of the platform — quietly fails at the worst possible moment.
The short answer: in a regulated industry, the audit system is owned by the regulated entity, not the AI application/system. The hospital owns it, not the clinical AI vendor. The bank owns it, not the SaaS underwriting platform. The insurer owns it, not the claims-triage tool. AI applications produce records into the enterprise’s audit fabric; they do not constitute it.
The reason is a property of regulatory liability that engineers often miss. When a regulator opens an investigation into an adverse outcome, the question they ask is not “what does your AI vendor’s audit system show?” It is “What does your audit show?” The regulated entity is on the hook. They can pursue the vendor contractually after the fact, but they cannot delegate their regulatory obligation. An audit system that lives only inside the vendor is, from the regulator’s perspective, not your audit system at all. It’s a third-party assertion you’ll be asked to corroborate from your own records.
This has architectural consequences that compound quickly:
Records must leave the AI application’s trust boundary. Audit records produced by the AI cannot live solely on the AI vendor’s infrastructure. They must be transported into the enterprise’s own audit fabric, signed by the producing application, and stored under the enterprise’s controls. If the vendor disappears tomorrow — acquired, bankrupt, breached, contract terminated — your audit obligations don’t disappear with them.
The schema is the contract, not the product. When you procure an AI application, the audit-record schema becomes part of the contractual artefact set. The vendor must produce records that conform to your schema, on your transport, signed with credentials you control. If the vendor cannot or will not do this, that is a procurement failure, not a technical detail to be negotiated later.
Internal AI applications get the same treatment as vendor ones. This is the discipline that’s hardest to enforce. When the team next door builds an internal AI tool, the temptation is to let them use whatever logging library they prefer and skip the formal audit pipeline. Don’t. The discipline only works if every AI producer — internal, vendor, hybrid — produces into the same audit fabric using the same schema.
The SaaS Question
Most regulated AI in production today is delivered as SaaS. This is not a problem in principle, but it makes the ownership question sharper.
When an AI application is delivered as SaaS, the inference happens on the vendor’s infrastructure, the model weights are the vendor’s, the prompt templates are sometimes the vendor’s, and the retrieval indices may be the vendor’s. The vendor has every operational reason to want to own the audit trail too — it’s where their telemetry lives, it’s where their improvement signals come from, it’s where they can demonstrate value back to the customer. Most SaaS contracts default to the vendor owning the audit logs.
This default is wrong for regulated buyers. Here’s what the contract and the architecture have to enforce instead:
The vendor produces audit records on the customer’s behalf. The records belong to the customer the moment they’re produced. The vendor may keep a copy for their own operational purposes (with appropriate data agreements), but the authoritative record lives in the customer’s audit fabric, not the vendor’s.
Records are produced over a customer-controlled channel. Even though the inference occurs on the vendor’s infrastructure, the audit record is signed by the application instance using credentials the customer issued (typically through a workload identity system like SPIFFE) and transported over a connection that the customer’s network controls. The vendor cannot quietly stop sending records, replay old records, or rewrite records in flight without leaving evidence.
Schema conformance is a contractual obligation. Vendors who want to sell into regulated industries have to produce records that match the customer’s audit schema, including the integrity envelope. This is one of the most common procurement gaps; it should be a non-negotiable line item before a contract is signed.
Customers can independently verify. The customer’s audit fabric must be able to verify, without consulting the vendor, that records are well-formed, signed by the correct producer, in correct sequence, and anchored. If verification depends on calling the vendor’s API, the verification is not independent.
Vendor model and policy updates produce audit events. When the vendor pushes a model update — or a prompt template change, retrieval corpus refresh, guardrail policy revision, routing rule change, or any threshold adjustment — that update itself becomes an auditable event. All of these can shift behaviour as much as a weights update can, and customers often discover the change only when output drifts. The customer’s audit fabric should capture which model version, prompt version, and policy configuration were active for each decision, with sufficient precision to enable a “before update” and “after update” comparison months later. Without this, the most consequential class of regulatory questions (“did the AI behave consistently before and after the change?”) becomes unanswerable.
The hard truth is that many SaaS AI vendors are not yet ready to meet these requirements. Their audit features are designed for their own operational needs, not for regulated customer evidentiary needs. This is a market gap that regulated buyers are increasingly closing through procurement leverage. If your vendor cannot meet these requirements today, the right move is to include them in the contract anyway, with a timeline, and make them a renewal condition.
Can Hospitals and Banks Afford a Different Audit System Per AI Vendor?
No. They cannot. And this is the operational truth that drives the whole architecture.
A typical mid-sized hospital today has anywhere from eight to twenty AI applications in some stage of deployment — sepsis detection, radiology triage, ambient documentation, billing copilots, clinical decision support, medication-error checking, scheduling optimisation, scribing, and so on. A bank has a similar or larger spread across credit decisioning, KYC, AML, fraud detection, customer service automation, and document understanding.
If each of those AI applications had its own audit system, the regulated entity would be operating eight to twenty different audit pipelines, with eight to twenty different schemas, eight to twenty different retention policies, and eight to twenty different reconstruction interfaces. When the regulator asks “show me every AI decision made about this patient between June and August,” the compliance team would have to query eight to twenty different systems, normalise the outputs, and hope the timestamps are reconcilable. That is an operational impossibility. It is also exactly the situation many enterprises are sliding into by default.
The alternative, and the only architecture that scales, is a single enterprise-owned audit fabric that every AI application — internal or vendor, in-house or SaaS — produces records into. The schema is owned by the enterprise. The transport is owned by the enterprise. The storage is owned by the enterprise. The reconstruction interface is owned by the enterprise. AI applications are producers; the audit fabric is the system of record.
This is the architecture that the rest of this post describes. The ownership question is what makes it real.
Seven tiers, each with its own technology choices, each owned and operated by the enterprise. Producers — whether internal teams or external vendors — conform to the published schema and produce into Tier 2’s transport. Everything from there is the enterprise’s responsibility. This is the architecture that lets a hospital with fifteen AI applications still answer a single regulatory question with a single query.
Transport Security: The Most-Attacked, Least-Discussed Layer
There is an obvious attack on the architecture above that nobody likes to talk about. Audit records are most vulnerable in the gap between when they are produced (inside the AI application) and when they are sealed into the chain (at Tier 4). If an attacker can tamper with records in that gap, the entire integrity story downstream becomes fiction. The hash chain is faithfully recording records that were already corrupted before they arrived.
This is why transport security in audit pipelines is a different problem from transport security in operational telemetry. For operational telemetry, you mainly care that data gets there; the occasional dropped span doesn’t matter. For audit records, you care that every record arrives in the form it was produced, is signed by the producer identity, is deduplicated, and is ordered within the relevant producer or decision stream — with globally consistent anchoring across streams handled at the Merkle batch layer. Any of those properties failing breaks the evidential value.
The minimum controls:
Mutually-authenticated transport (mTLS everywhere). The producer authenticates the receiver, and the receiver authenticates the producer. No anonymous publishers. No shared bearer tokens. This eliminates the “we accepted records from an attacker who claimed to be the AI app” failure mode.
Workload identity, not service accounts. Use a workload identity system (SPIFFE/SPIRE in Kubernetes-heavy environments, cloud-native equivalents like AWS IAM Roles for Service Accounts or Azure Workload Identity elsewhere) so that each AI application instance has a verifiable cryptographic identity. The signature on the audit envelope is verifiable against that identity. If the AI application is compromised and an attacker tries to produce records from a different identity, the signature check fails.
Signed envelopes, signed inside the application boundary. The signature on the audit envelope is computed within the producing application, using a key that the application controls, before the record leaves. If signing occurs at the network edge (a sidecar or gateway), then anyone who can inject between the application and the edge can produce unsigned-but-accepted records. Sign at the source.
Idempotent sequence IDs and replay detection. Every record has a decision_id that is unique identifier within the producing application. The gateway dedupes on this ID. An attacker who replays records will produce duplicates that the gateway rejects. Without this, an attacker who captures a legitimate record can replay it to manufacture false evidence.
At least once delivery, not at most once. The transport must guarantee delivery and retry on failure, with the gateway’s dedupe handling the resulting duplicates. The opposite (at-most-once) silently drops records in the face of transient failures, and silent loss is the worst possible failure mode for an audit system.
Backpressure that fails closed, not open. If the transport pipeline is overloaded and cannot keep up, the producing AI application must either block on the audit submission or refuse the inference. The pattern that must not happen is “fire and forget the audit, return the answer to the user.” That pattern produces actions without records, which is the most legally damaging failure mode possible. Fail closed: if you can’t produce the audit, you don’t produce the action.
These are not unusual controls. They’re standard for high-integrity transactional systems — banks have used them for decades to record transactions. They are still missing from most AI observability deployments because the deployments grew out of an operational logging culture, where dropped records are an inconvenience rather than a liability.
The Audit Record Workflow, End to End
Putting it all together, this is what the journey of a single audit record looks like — from the moment the model produces an output to the moment the record is permanent, anchored, and queryable.
Read this flow as a chain of integrity properties. Each stage adds or preserves a property; the combination is what makes the final record evidential rather than merely informational.
A record that has only some of these properties is not partial evidence — it’s fragile evidence, in ways that can be hard to spot until they’re tested under adversarial conditions. The point of the architecture is that every stage has its own attacker profile and its own control, and the controls compose. If a record is forged outside the producer identity, the gateway’s signature verification catches it. If the producer itself is compromised, no single signature check will save you — the control then shifts to key isolation, runtime attestation, anomaly detection, sequence monitoring, and downstream reconciliation against the actions the AI actually took. If the gateway is compromised, the external witness catches the silent rewrites. If the external witness is compromised, choose two witnesses. The architecture degrades gracefully under partial failure, which is what “evidential” actually means in operational terms.
The combined architecture gives you something specific: the ability to take any historical audit record, walk the hash chain to its enclosing Merkle batch, fetch the externally-witnessed root, and produce a cryptographic proof that the record existed in its current form at the time of anchoring. That is the kind of evidence package a regulator, auditor, or court can evaluate.
OpenTelemetry: Yes, But Not For This
So far, this post has built up a custom-looking pipeline: producer SDKs, signed envelopes, gateways, hash chains, Merkle anchors, and immutable storage. A reasonable question at this point is, “Doesn’t OpenTelemetry already do most of this?” The answer is no, and the why is worth understanding clearly — because OTel is going to be in your stack anyway, and the question isn’t whether to use it but where to draw the line between what OTel handles and what the audit fabric handles.
OpenTelemetry is the right answer to most observability questions in 2026. It is not, by itself, the right answer to regulated AI audit trails. The distinction matters because most teams default to OTel and end up with an audit posture that is operationally excellent but legally indefensible.
What OTel does well: distributed tracing across the AI request path, latency and throughput metrics, correlation IDs that link your gateway to your model serving layer to downstream actions, and structured event emission in a well-understood vendor-neutral format. For operational observability of AI systems, OTel is excellent — and the emerging OpenTelemetry semantic conventions for GenAI (covering attributes like gen_ai.system, gen_ai.request.model, gen_ai.usage.input_tokens, etc.) make it easier than before to consistently capture LLM-specific telemetry, even though significant portions of those conventions are still in active development.
What OTel does not do: provide immutability, provide cryptographic integrity guarantees, enforce retention policies that distinguish operational telemetry from audit-grade records, or guarantee that what you emitted survives in the form you emitted it.
The right pattern is to use OTel as the instrumentation and correlation layer, and to route audit-grade records to a separate immutable sink that lives outside the trace and metrics pipeline.
In practice, this looks like:
Your application emits OTel spans for every model call, with the GenAI semantic-convention attributes attached. These flow to your standard observability backend (Datadog, Honeycomb, New Relic, your self-hosted Jaeger/Tempo, whatever).
For decisions that meet the audit-grade threshold (typically: any decision that affects a patient, transaction, customer, or downstream action), the application also emits a separate audit record — typically as a structured event to a dedicated Kafka/Kinesis topic — that flows into the immutable audit pipeline described above.
The two records share a correlation ID (the OTel trace ID is fine for this), so an investigator can pivot between operational telemetry and audit evidence.
Two failure modes to avoid:
Don’t try to make your trace store the audit store. APM and tracing platforms are designed for short-retention, high-cardinality, mutable data. They will happily lose your spans, sample them, age them out, or schema-evolve them under you. None of those behaviours is compatible with audit requirements.
Don’t double-write everything to both stores. Decide which records cross the audit-grade threshold and route only those records. A retrieval that returns no results and triggers no action is operational telemetry; the same retrieval that grounds a clinical recommendation is an audit event. Same span, different routing.
The PII Problem (What “Masked” Means In Court)
This is the section where most AI observability discussions go quiet, because the honest answer is uncomfortable.
Regulated AI systems process personal data. The audit trail therefore captures, references, or is otherwise entangled with personal data. Privacy law (GDPR’s Article 5, HIPAA’s minimum necessary standard, the DPDP Act’s purpose limitation, every analogous regime) requires that personal data be retained only as long as necessary for the purpose collected, in the minimum amount necessary, with appropriate safeguards. None of those laws care that your audit retention requirements are longer than your data retention requirements.
You cannot solve this by “just masking everything.” There are at least four different things that get called masking, and they have very different properties.
Redaction (irreversible). Replace Nitin Mallya, Aadhar number 9876 5432 1000 6723 with [NAME], [AADHAR NUMBER]. Easy. Cheap. And often fatal to your audit trail’s reconstructability, because if a court asks “what did the AI decide for Nitin on June 14th?”, you may not be able to answer from the audit trail itself. You’ve made a record of some decision involving some patient, which is not what a regulator is asking for.
Hashing (deterministic but not reversible). Replace 9876 5432 1000 6723 with sha256("9876 5432 1000 6723"). Better. The same patient now produces the same hash across records, so you can correlate decisions for the same person without storing the identifier. But there’s a gotcha: hashes of small identifier spaces (account numbers, anything with limited entropy) are trivially reversible by an attacker who can rainbow-table the input space. For most regulated identifiers, raw hashing is barely better than plaintext from a privacy standpoint. You need a salt or HMAC key, stored separately, with its own access controls.
Tokenisation (reversible, with controlled access to the mapping). Replace 9876 5432 1000 6723 with token tok_8a2f3c…, and store the mapping tok_8a2f3c → "9876 5432 1000 6723” in a separate, tightly access-controlled token vault. This is the pattern that actually works in regulated environments. The audit record contains the token, which is meaningless without the vault. The vault has its own access controls, audit logs, and can be subject to legal hold. When a court asks “what did the AI decide for patient X?”, you authorise a single, logged dereferencing of X’s token to find their records — and you have a logged record of who looked, when, and why.
Format-preserving encryption. Replace 9876 5432 1000 6723 with 6789 2354 0001 3276 (still sixteen digits, still passes type validation, but encrypted under a key you control). Useful when downstream systems need data of the right shape but not the actual value. More complex than tokenisation; rarely worth the complexity unless you have a specific schema-compatibility constraint.
For audit trails that must support lawful reconstruction, the right default is tokenisation, with the token vault treated as a first-class compliance artefact: separately encrypted, separately access-controlled, separately backed up, with its own audit log of every dereferencing operation.
Now the part nobody likes to talk about.
What “masked” means when the litigation arrives. When opposing counsel deposes your CTO and asks “did your AI system make a decision involving my client on June 14th, 2024?”, the answer your team gives depends entirely on which masking strategy you chose.
If you redacted: your honest answer is “we don’t know.” That answer is not a defence. In some jurisdictions, the inability to produce records that you should reasonably have kept is itself adverse to your case. Spoliation is the legal term, and it has consequences.
If you hashed: your honest answer is “we can check, but it depends on the entropy of the identifier and the strength of our salt.” This is a fragile answer to give in court.
If you tokenised: your honest answer is “yes, here are the records.” The vault dereferencing produces evidence. The vault’s own audit log proves the dereferencing was authorised and lawful.
The choice of masking strategy is therefore not just a privacy choice. It is a litigation-readiness choice. Teams that redact-by-default are choosing privacy maximalism at the cost of being unable to defend themselves when the case comes. Teams that tokenise correctly are choosing a strategy that satisfies privacy regulators (the audit store contains no decryptable PII) and preserves their ability to respond to lawful production demands (the vault is the controlled choke point).
This nuance does not show up in the privacy-by-design literature. It shows up in the discovery phase of every AI lawsuit that has yet to be filed.
Retention
One more piece. How long do you keep all of this?
This is not an engineering decision. It is a legal and compliance decision that engineering implements. The single most common pathology in regulated AI observability is engineering deciding retention based on storage cost, then discovering after a lawsuit that legal would have set retention to a longer duration.
The right default architecture is tiered retention, set by record type, governed by legal and compliance:
Operational telemetry (OTel spans, metrics, ops logs): days to weeks, set by SRE for incident response needs.
Audit metadata records (the structured records described above, minus the raw payloads): typically the longest of (regulatory mandate for the industry, statute of limitations for likely litigation, internal policy). For healthcare AI in most jurisdictions, this means 6-10 years minimum. For banking AI, often longer.
Raw payloads (the actual inputs and outputs the audit metadata references): governed by data minimisation requirements; often much shorter than audit metadata. The hash in the audit record proves what was scored, even after the raw payload is deleted.
Token vault: governed by the same regime as the underlying personal data, with the additional constraint that it must outlive the audit records that reference it (otherwise the audit records become unreadable).
Legal hold overrides everything. When a litigation hold notice arrives, deletion stops for everything in scope, regardless of what the default retention policy says. The system must support this as a first-class operation, not as a panicked all-hands at 11pm on a Friday.
The other thing engineering does not get to decide: deletion. In regulated environments, “we deleted the data to save cost” is not a defence; it is an admission. Any deletion policy must be reviewed by legal, executed automatically by the system (not by engineers running scripts), and itself logged in the audit trail. The fact of deletion, the policy that authorised it, and the records affected — all of it goes in the audit trail.
Eat This, Not That
The whole architecture in one image, for the people who got this far.
What This Buys You
A regulated AI observability stack built this way is not just a compliance artefact. It is a system property.
It buys you the ability to answer, with evidence, the question that started this post: “what did the AI decide on the morning of the admission, and on what basis?” It buys you the ability to defend that answer in front of a regulator who has read your validation protocol and a court that has not. It buys you the ability to detect drift, debug failures, and reconstruct incidents long after the team that built the system has moved on. It buys you the ability to comply with privacy law and litigation requirements simultaneously, which most teams treat as a contradiction and is not.
It also buys you the right to deploy AI in workflows where the cost of being wrong is asymmetric — which, as Part 1 of this series argued, is the only kind of deployment that actually moves the needle for regulated industries.
The architecture is not free. Engineering effort is real. The token vault is a non-trivial system. The Merkle anchoring requires choosing and operating a witness. The schema discipline requires governance. None of this is what your data engineers signed up for when they joined.
But the alternative is the conversation the CTO had at the start of this post. Multiplied across an industry that is now deploying AI into the workflows that matter. The teams that build the audit trail right will at least enter their first lawsuit with evidence instead of explanations. The teams that don’t will become the case study that justifies the next round of regulation.
Build the audit trail. Build it now. Build it before the lawyers arrive — because they will.
FAQ: Regulated AI Audit Trails
Ten questions a senior practitioner is likely to ask after reading this article. Answers are calibrated for technical leaders, architects, and CISOs — not for cryptography specialists, but not for beginners either.
What is a Merkle tree, and why does this architecture need one?
A Merkle tree is a way of producing a single short hash — typically 32 bytes — that cryptographically commits to a large set of records. You hash each record individually, pair the hashes and hash the pairs, then pair those and hash again, and so on until you reach a single root hash. If any record in the original set is altered, the root changes. If the root hasn’t changed, the records haven’t either.
The architecture needs Merkle trees for one practical reason: cost. Without them, you would either have to publish every audit record to an external witness (expensive and slow at the volumes regulated AI generates) or trust that your own storage layer hasn’t been tampered with (defeats the point). With a Merkle tree, you batch thousands of records together and only publish the root externally. A 32-byte hash now stands as cryptographic evidence for the integrity of the entire batch. The maths means you can prove any individual record’s inclusion in the batch with a small “Merkle proof” — a handful of hashes — without needing the rest of the batch.
Merkle trees are not exotic. They are how Bitcoin organises transactions in a block, how Git tracks file changes, and how Certificate Transparency logs prove the integrity of TLS certificates issued across the public internet. The pattern is decades old and well-understood. The only new thing is applying it to AI audit records.
Why OpenTimestamps vs. “putting things on the blockchain”?
OpenTimestamps is a free, open protocol that lets you anchor a hash to the Bitcoin blockchain without paying transaction fees, running a node, or publishing anything sensitive. It works by aggregating large numbers of submitted hashes into its own Merkle tree, and committing only the root of that tree to Bitcoin. Each user gets back a small proof file that, combined with the public Bitcoin blockchain, proves their hash existed at a specific point in time.
The distinction from “putting things on the blockchain” matters. People hear “blockchain” and imagine storing the actual data on-chain — which would be expensive, slow, and would expose sensitive content publicly. OpenTimestamps does the opposite: nothing about your audit records goes anywhere near Bitcoin. Only a hash of a hash of a hash, with no way to reverse it back to your data, ever touches the public chain. What you get is a proof of existence — evidence that this hash existed at this time, witnessed by an entire global network — without any data exposure.
For most regulated organisations, OpenTimestamps is the maximally adversarial-resistant external witness. Nobody can rewrite Bitcoin’s history to falsify your audit trail. The trade-off is operational complexity (you need to manage the proof files) and the optics question — some regulated industries are still squeamish about “blockchain” in any form, regardless of the technical reality.
What is RFC 3161, and why should I trust it?
RFC 3161 is an IETF standard from 2001 that defines how to get a trusted third party — called a Time Stamping Authority, or TSA — to digitally sign a hash with a precise timestamp. You send the TSA a hash, they sign it along with the current time using their private key, and the resulting signed object proves that this hash existed at this time, attested to by this TSA. You can verify the signature later using the TSA’s public certificate without contacting the TSA again.
Trust comes from the same place it comes from for TLS certificates: a chain of cryptographic signatures back to a root authority that auditors and courts already accept. Most national post offices, several governments, and a number of commercial vendors operate RFC 3161 TSAs. The standard has been used in regulated industries for over two decades — code signing, document signing, e-invoicing, court-admissible electronic evidence — and the legal weight of an RFC 3161 timestamp is well-understood in most jurisdictions.
For AI audit trails, RFC 3161 is the boring, mature, defensible option. It is what your legal team will be most comfortable with, because they have already seen it accepted in non-AI contexts. The cost is choosing a TSA vendor and integrating with their API, both of which are routine.
What’s the difference between WORM storage and a managed ledger?
WORM (Write Once, Read Many) storage is a property of an object store: once you write a file, you cannot modify or delete it until a configured retention period expires. AWS S3 Object Lock, Azure Immutable Blob Storage, and Google Cloud Storage Bucket Lock all implement WORM mode. The cloud provider enforces the immutability — your application code cannot bypass it.
A managed ledger is a different category of service. Azure Confidential Ledger is the canonical example. It provides an append-only data structure with built-in cryptographic integrity (hash chain, Merkle proofs), runs inside hardware-secured enclaves, and produces verifiable receipts for every entry. The provider gives you not just immutable storage but also the integrity proofs as a service.
The architectural difference: WORM gives you immutability, but you have to build the integrity layer (hash chain, Merkle anchoring) yourself on top. A managed ledger gives you both. The trade-off is cost (managed ledgers are typically more expensive per write than object storage), trust boundary (you’re trusting the cloud provider’s enclave attestation rather than your own cryptography), and lock-in (managed ledgers don’t have a portable standard — you can’t easily migrate from one provider’s ledger to another).
The pragmatic default for most regulated AI audit fabrics is WORM object storage paired with independent timestamping (RFC 3161 or OpenTimestamps). Managed ledgers make sense when the operational simplicity is worth the cost premium and the cloud-trust dependency is acceptable.
What is SPIFFE/SPIRE, and why not just use API keys?
SPIFFE (Secure Production Identity Framework For Everyone) is an open standard for issuing cryptographic identities to software workloads — services, containers, functions — automatically, at runtime, without humans handling secrets. SPIRE is the reference implementation. Together they let every running instance of an AI application have its own short-lived, verifiable cryptographic identity, rotated continuously, without any team ever needing to manage an API key.
The alternative — API keys — has three problems that matter for audit. First, API keys identify the application, not the instance; if you have ten copies of an AI service running, they all sign records with the same key, so an attacker who compromises one instance can produce records that are indistinguishable from any of the others. Second, API keys are long-lived; if one leaks (and they do leak — into logs, into git history, into screenshots), the attacker has months or years before rotation. Third, API keys are bearer tokens; anyone who holds the token can act as the identity. There is no cryptographic proof of who is currently using the key.
SPIFFE solves all three. Each instance has its own identity. Identities are short-lived (typically rotated every few hours). Authentication uses asymmetric cryptography, so possessing a SPIFFE identity means controlling the private key, not just holding a token someone copied. For audit records, this means the signature on each record traces to a specific instance, at a specific time, with cryptographic guarantees that are dramatically stronger than “we trust whoever sent us a valid API key.”
You don’t strictly need SPIFFE — cloud-native equivalents (AWS IAM Roles for Service Accounts, Azure Workload Identity, GCP Workload Identity Federation) provide similar guarantees with provider lock-in. The principle matters more than the implementation: workload identity, not service accounts; short-lived credentials, not long-lived secrets; per-instance attribution, not application-wide.
What does “fail closed” actually mean in production?
Fail closed means: if the system cannot perform the action safely, it does not perform it. Fail open means: if the system cannot perform the action safely, it performs it anyway and hopes for the best.
In the context of audit pipelines, fail closed means: if your AI application cannot successfully write an audit record (transport is down, gateway is unreachable, signing key is unavailable), the application blocks the inference or refuses to return the answer — until the audit can be written. Fail open means the application returns the answer to the user and tries to write the audit later, accepting silent loss as a possibility.
Most operational systems default to fail open because it improves availability. For audit pipelines in regulated AI, fail open is the worst possible failure mode: it produces actions without records. An AI agent took an action, the user saw it happen, the downstream system was updated — but there is no audit trail of the decision. From a regulator’s perspective, this is indistinguishable from the system having taken an unauthorised action with the team trying to cover it up. Even if the cause was a benign infrastructure hiccup, the absence of evidence is itself adverse to the organisation’s case.
In production, fail closed is implemented as: the audit submission is on the synchronous path of the inference. If the submission fails after retries, the inference returns an error to the user (or queues for human review, depending on the workflow). The team will hate you when the audit pipeline has an outage and the AI features start failing. They will hate you less than a regulator finding gaps in your audit trail.
How is this different from logging?
Logging is for engineers debugging the system. Auditing is for proving what the system did to someone who wasn’t there.
The differences cascade through the architecture. Logs can be edited or deleted (often by the same engineers who write them); audit records cannot. Logs can be sampled or dropped under load; audit records must be guaranteed to arrive, in full, in order, exactly once. Logs are typically kept for weeks; audit records are typically kept for years. Logs use whatever schema the developer thought useful; audit records conform to a published schema that legal and compliance have signed off on. Logs are accessed by anyone on the team with the right roles; audit records have access controls, dereferencing audit logs, and legal-hold overrides.
Most teams treat AI audit as “structured logging with a longer retention.” That treatment fails the first time someone asks “prove that nobody on your team modified this record.” Logs cannot prove that. Auditing is logging plus integrity, plus governance, plus retention discipline, plus access controls, plus the cryptographic infrastructure to defend the record’s authenticity. The architecture in the main post is what gets you from one to the other.
Can we use blockchain for the whole audit trail instead?
In principle, yes. In practice, no.
Blockchains have several properties that look attractive for audit: immutability, cryptographic integrity, distributed witness, well-understood verification. But they have several properties that disqualify them for regulated AI audit at scale.
Cost is the first problem. Public blockchains charge per write, often substantially. Writing every audit record to a public chain would bankrupt the audit budget within weeks of going to production. Private or permissioned chains (Hyperledger, Quorum, etc.) avoid the per-write fees but lose the adversarial-resistance property — they’re now back inside your trust boundary, with all the same questions you’d have about WORM storage but with much more complex operations.
Privacy is the second problem. Once data is on a public chain, it is on the chain forever, visible to everyone, regardless of what privacy law says. You cannot delete it on a GDPR erasure request. You cannot tokenise it after the fact. Hashes of personal data, written carelessly, can be reversed by anyone with the patience to brute-force a small input space. The chain is the worst possible place to store anything that touches PII.
Throughput is the third. Public chains process tens of transactions per second. A regulated AI deployment may produce hundreds or thousands of audit records per second. The mismatch is several orders of magnitude.
The right pattern is what the main post describes: keep the audit records in your own infrastructure, build a hash chain locally, batch the chain heads into Merkle roots, and only commit the Merkle roots to a public chain (via OpenTimestamps) or a managed ledger. The chain is used as a witness, not as a database. This gets you the integrity property without the cost, privacy, or throughput problems.
Building Blocks: Trillian vs. Sigstore Rekor vs. Build Your Own?
All three solve the same problem: append-only, ordered, cryptographically verifiable storage for audit records. The differences are in maturity, intended use case, and operational footprint.
Trillian is Google’s open-source verifiable log implementation. It is what powers Certificate Transparency — the global infrastructure that monitors TLS certificate issuance to detect rogue certificate authorities. It is battle-tested at internet scale, well-documented, and designed to be operated by people who take audit infrastructure seriously. The downside is that it’s a significant operational commitment; running Trillian well requires real expertise.
Sigstore Rekor is part of the Sigstore project, originally designed for software supply-chain transparency (signing open-source artefacts, recording attestations). It is built on the same verifiable-log primitives as Trillian but with a more opinionated API, easier deployment, and a smaller operational footprint. For organisations that want a verifiable log without operating infrastructure at the Trillian level of seriousness, Rekor is the more pragmatic choice.
Rolling your own is the right choice when your scale is small, your team has the cryptographic expertise to build it correctly, and you have specific requirements that don’t fit either Trillian or Rekor. The risk is that hash-chain writers are easy to write and hard to write correctly; subtle bugs around concurrent writes, replay handling, or signature verification can quietly corrupt the integrity of the entire chain. If you go this route, treat it as security-critical code, with the review and testing discipline that implies.
The pragmatic default for most regulated AI audit fabrics is Sigstore Rekor — it gets you most of what Trillian provides at a fraction of the operational complexity, and it has a healthier ecosystem than custom code.
How does this interact with GDPR’s right to erasure?
This is the question with no clean answer, and any vendor or consultant who tells you otherwise is selling something.
GDPR Article 17 grants data subjects the right to have their personal data erased under certain conditions. Audit retention requirements — for regulated industries, often six to ten years or more — create personal data that the organisation has a legal obligation to keep. The two regimes can collide directly.
The architecture in the main post is designed to handle this collision in the cleanest way the law allows, but it does not eliminate the tension. The pattern: personal data lives in the raw payload store and the token vault, not in the audit-record metadata. The audit records themselves contain only tokens and hashes. When an erasure request arrives and is determined to be valid (which is a legal determination, not a technical one), the personal data in the raw payload store can be deleted, and the token vault entries for that data subject can be deleted. The audit metadata records remain, with their tokens now pointing at vault entries that no longer exist. The records still prove what happened — some AI decision involving some (now-erased) data subject — but the personal connection is severed.
This is sometimes called “crypto-shredding” — using key destruction or vault-entry destruction to render previously-encrypted data effectively unrecoverable. Whether it satisfies GDPR Article 17 in any specific case is a legal determination that depends on the jurisdiction, the nature of the regulated retention obligation, the specific data, and how courts and Data Protection Authorities have interpreted “erasure” in similar cases. In some regulated contexts, the regulated retention obligation overrides the erasure right. In others, it doesn’t.
The architectural answer is therefore: build the system so that erasure is possible without breaking the audit trail. Whether to actually exercise that capability in any specific case is a question for legal counsel, not engineering. Engineering’s job is to make sure the choice is available.